El uso de grandes modelos de lenguaje (LLM) para generar recomendaciones empresariales es un campo de creciente interés, sobre todo porque estos modelos se adaptan a necesidades específicas de los consumidores, como proporcionar listas de negocios según una solicitud específica. En este estudio exhaustivo, examinamos el rendimiento de ChatGPT-4o, un modelo basado en GPT-4o de OpenAI, al generar listas de negocios bajo diferentes condiciones de solicitud, centrándonos específicamente en una solicitud centrada en los «mejores dentistas de Las Vegas». En España no se ha podido ni se ha realizado aún dicho estudio.
El objetivo implica un proceso que creamos, llamado multimuestreo, mediante el cual iteramos una indicación varias veces para tomar instantáneas que permitan rastrear y medir las empresas. Además, analizamos cómo la presencia o ausencia de capacidades de navegación web y las variaciones en la redacción de las indicaciones afectan la calidad, la consistencia y la precisión de las recomendaciones empresariales proporcionadas por el LLM.
El estudio se realizó con herramientas de software personalizadas diseñadas para analizar las respuestas de ChatGPT-4o en diferentes configuraciones. Los resultados ofrecen información sobre cómo se pueden aprovechar herramientas LLM como GPT-4o para generar recomendaciones empresariales fundamentadas en diferentes condiciones operativas.
En este artículo
Diseño experimental
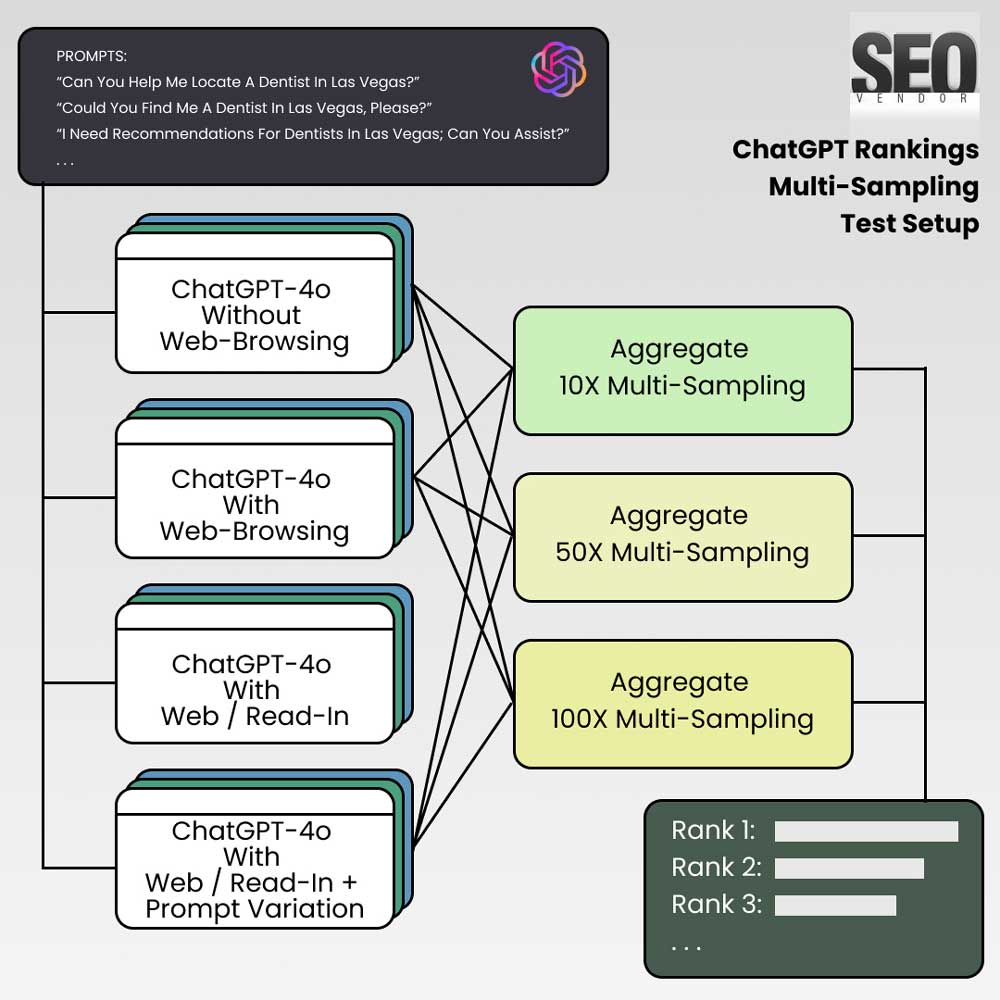
El estudio empleó una serie de experimentos con cuatro condiciones bajo las cuales se le pidió a ChatGPT-4o que generara una lista de negocios recomendados (en este caso, dentistas en Las Vegas). Las condiciones fueron las siguientes:
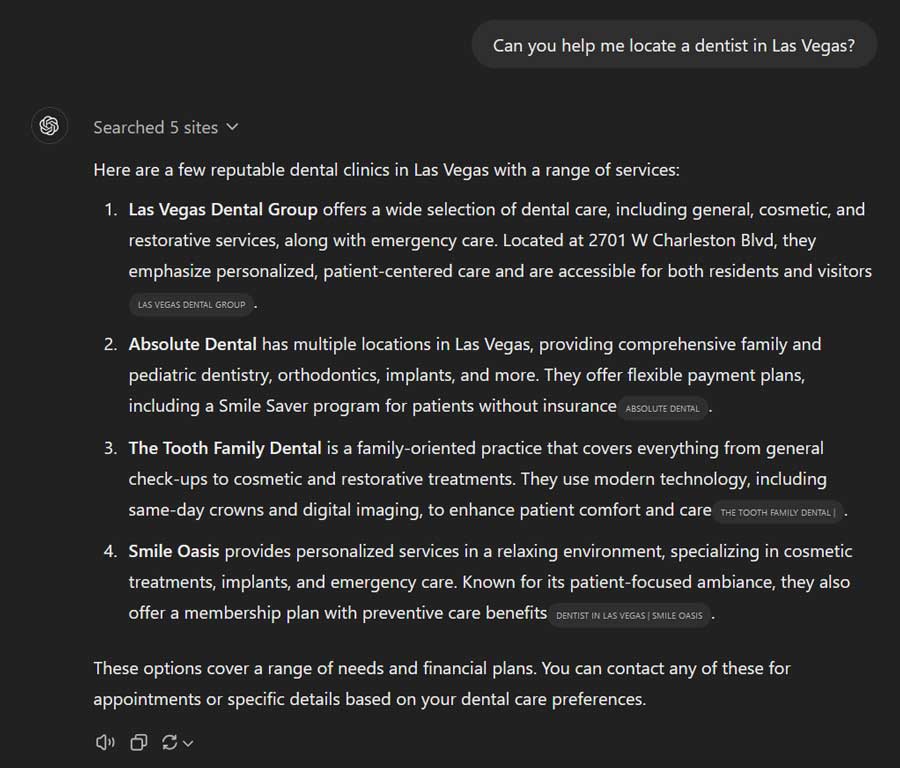
- ChatGPT-4o sin navegación web (ChatGPT gratuito) : En esta condición, se utilizó GPT-4o sin acceso a datos web en tiempo real ni a funciones de navegación. El modelo generó respuestas basándose únicamente en la información de sus datos de entrenamiento.
- ChatGPT-4o con búsqueda web (ChatGPT de pago) : En este caso, GPT-4o contaba con acceso a funciones de navegación web a través de Bing. Esto le permitió complementar sus datos de entrenamiento con información en tiempo real, lo que teóricamente le permitía ofrecer recomendaciones más precisas y actualizadas.
- ChatGPT-4o con lectura de navegación web (SearchGPT) : En esta condición, GPT-4o no solo pudo realizar una búsqueda web, sino que también pudo leer artículos y páginas web específicos, como «Los mejores dentistas de Las Vegas». Esta capacidad adicional de lectura se diseñó para que el modelo pudiera ofrecer recomendaciones basadas en la recuperación directa de datos de páginas relevantes.
- ChatGPT-4o con lectura de navegación web + variación de la indicación (SearchGPT) : En este escenario, el modelo se probó con diez versiones ligeramente diferentes de la indicación. Cada versión solicitaba recomendaciones de dentistas en Las Vegas con diferentes formulaciones, desde «¿Puede ayudarme a encontrar un dentista en Las Vegas?» hasta «¿Podría buscar dentistas que ejerzan en Las Vegas?». El objetivo de usar variaciones de la indicación era comprobar cómo diferían las respuestas del modelo según la redacción y evaluar el impacto de cambios sutiles en la consistencia y la fiabilidad del resultado.
¿Por qué realizar este experimento?
ChatGPT, y SearchGPT, que pronto se integrará, tienen el potencial de revolucionar la forma en que encontramos y buscamos marcas y empresas. Observamos una falta de información en línea que evalúe la eficacia de los grandes modelos lingüísticos para comprender las marcas, las empresas y sus sitios web asociados.
Dado que, al momento de escribir este artículo, Google tiene una capitalización de mercado de 2,06 billones de dólares y ChatGPT es la plataforma de más rápido crecimiento en la historia, es probable que a medida que más personas usen OpenAI para encontrar respuestas, las empresas se interesen más en el potencial comercial de los LLM.
Si bien creemos que los motores de búsqueda probablemente seguirán con nosotros, es difícil evaluar el potencial de marketing en plataformas LLM sin la valiosa información que puede aportar la realización de experimentos como este.
Potencial de negocio
Los modelos de lenguaje grandes como ChatGPT aprenden de una vasta biblioteca de conocimientos. Por ello, consideramos la facilidad para encontrar una marca como «Nike» en comparación con empresas más pequeñas, que tienen menos probabilidades de ser conocidas. Solo en EE. UU., existen 33 millones de empresas, según la Administración de Pequeñas Empresas de EE. UU.
- Si, hipotéticamente, el 10% de estos negocios se encuentran usando ChatGPT (con SearchGPT), serían 3,3 millones de negocios. Esto incluye empresas grandes y pequeñas, ya sean compañías de la lista Fortune 500 o pequeños comercios.
- Según The Verge, en agosto de 2024, ChatGPT tenía más de 200 millones de usuarios activos semanales, el doble de los 100 millones que tenía en noviembre de 2023.
- Podemos proyectar el crecimiento de usuarios de ChatGPT teniendo en cuenta los avances tecnológicos, la competencia y la saturación del mercado.
- A este ritmo, en 2029, el 20% de todas las empresas de EE. UU. se verán afectadas por 493 millones de usuarios de ChatGPT.
Potencial comercial de ChatGPT
| Año | Número de usuarios (millones) | Empresas encontradas en SearchGPT | Impacto empresarial (%) |
| 2024 | 200 | 3300000 | 10 |
| 2025 | 260 | 3795000 | 12 |
| 2026 | 325 | 4364250 | 13 |
| 2027 | 390 | 5018887 | 15 |
| 2028 | 448 | 5771721 | 17 |
| 2029 | 493 | 6637479 | 20 |
A partir de estas proyecciones, nos decidimos por el mercado local de Las Vegas, centrándonos únicamente en los dentistas de la zona, ya que predecimos que probablemente estará entre el 20 % de las empresas afectadas para 2029.
Al centrarnos en un mercado de servicios localizado, también podemos evaluar con mayor profundidad las capacidades de conocimiento de ChatGPT. Este enfoque puede mostrar cómo millones de empresas podrían, en el futuro, considerar ChatGPT o programas LLM similares como una oportunidad para captar nuevos clientes.
Variaciones de indicaciones
Las variaciones de las indicaciones incluidas en la cuarta condición se diseñaron para simular las formas naturales en que los usuarios pueden buscar información similar. Estas incluían:
- «¿Puedes ayudarme a encontrar un dentista en Las Vegas?»
- “¿Podrías encontrarme un dentista en Las Vegas, por favor?”
- Necesito recomendaciones de dentistas en Las Vegas. ¿Podrían ayudarme?
- “Por favor busque un dentista ubicado en Las Vegas.”
- «¿Podrías indicarme un dentista en el área de Las Vegas?»
- Estoy buscando un dentista en Las Vegas; ¿puedes ayudarme a encontrar uno?
- «¿Puedes buscarme un dentista en Las Vegas?»
- Necesito un dentista en Las Vegas; ¿podrías encontrar uno?
- «¿Puedes encontrarme un dentista de buena reputación en Las Vegas?»
- «¿Podrías buscar dentistas que ejerzan en Las Vegas?»
Los mensajes siempre se probaron de forma independiente, lo que significa que no hay memoria residual entre cada prueba o muestreo.
Estrategia de muestreo múltiple
Cada una de las cuatro condiciones se probó con múltiples muestras para garantizar la consistencia y fiabilidad de los resultados. En concreto, se solicitó a GPT-4o:
- 100X: Se realizó un seguimiento del muestreo durante 100 iteraciones.
- 50X: Se realizó un seguimiento del muestreo durante 50 iteraciones.
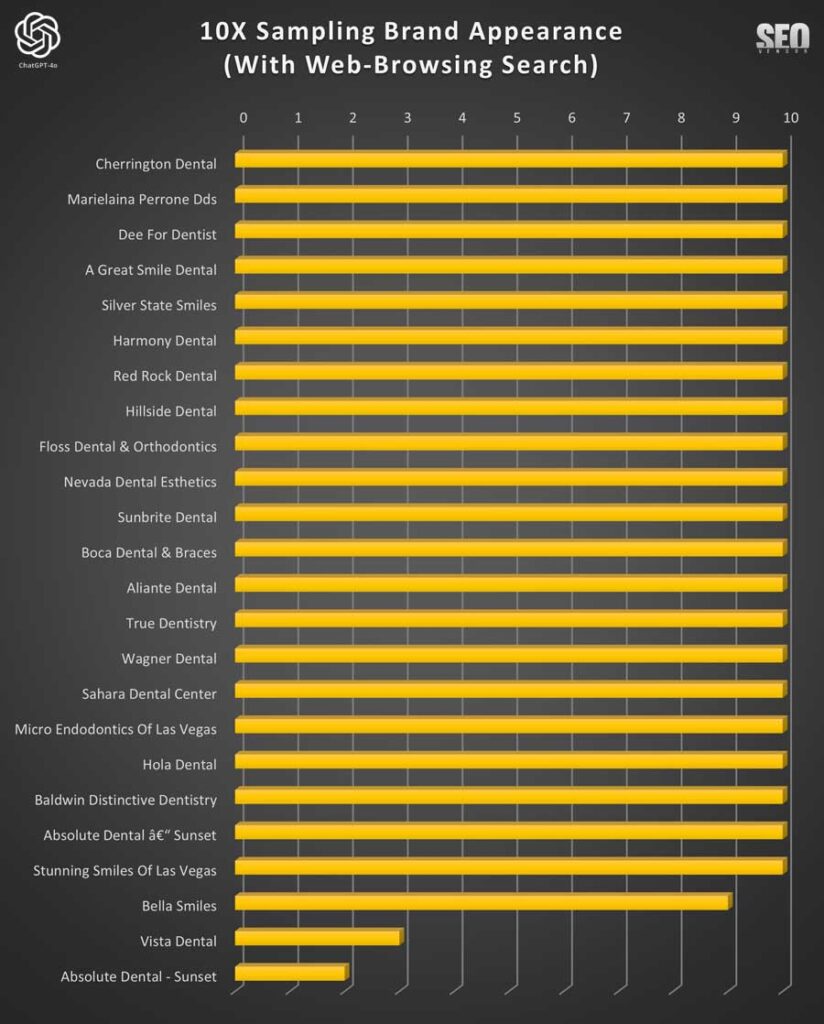
- 10X: Se realizó un seguimiento del muestreo durante 10 iteraciones.
Esto dio como resultado un total de doce experimentos diferentes (3 multimuestras × 4 condiciones), lo que generó más de 5700 filas de datos para su análisis. Los datos se extrajeron, recopilaron y analizaron exhaustivamente para determinar patrones, precisión, consistencia y variaciones en las respuestas en las diferentes condiciones.
Cómo rastreamos una empresa
En todas nuestras pruebas, medimos tanto la identidad de la marca como la del sitio web. Validamos las marcas y los sitios web para garantizar que sean reales y no manipulados por la IA. Si bien se eliminaron la mayoría de los resultados manipulados, en algunos gráficos agregados, no excluimos intencionalmente una o dos empresas genéricas o ficticias para demostrar su posicionamiento. En estas circunstancias, identificamos estas anomalías para comparar su frecuencia de aparición con la de las empresas reales.
Definición de rango en ChatGPT
Luego, definimos la clasificación en ChatGPT según la primera aparición. El resultado se presentaba generalmente en formato de oración natural, con los resultados representados en una lista que incluía el nombre de la empresa y el sitio web (si estaba disponible).
Los chatbots como ChatGPT utilizan entradas basadas en indicaciones y generalmente brindan respuestas de texto en forma de texto estructurado, a diferencia de los motores de búsqueda, que tradicionalmente definen los resultados de búsqueda en un formato de lista.
Dado que las preguntas que hacemos son sobre dentistas en Las Vegas, ChatGPT proporcionó múltiples respuestas y las estructuró en una lista para nosotros.
Versión de GPT
Todas las pruebas se realizaron con chatgpt-4o-latestLa versión del modelo siempre se conecta a la última versión de GPT-4o utilizada en ChatGPT. Las pruebas finales se realizaron en septiembre y octubre de 2024. Los resultados futuros pueden variar ya que ChatGPT-4o se actualiza con frecuencia.
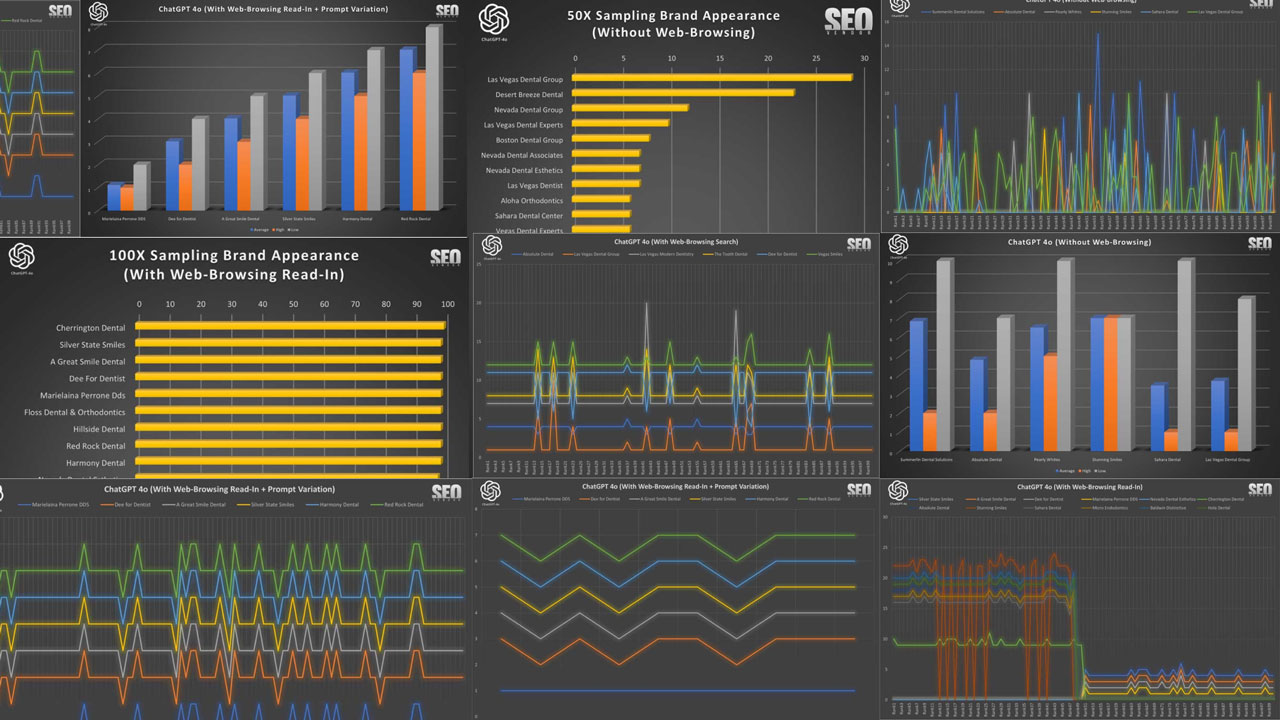
Resultados del muestreo iterativo 50X
El objetivo de esta prueba fue adquirir la apariencia de un negocio, en este caso una clínica dental, mediante 50 solicitudes y midiendo la apariencia resultante de los nombres de los negocios y su sitio web. Las pruebas se realizaron con una herramienta de validación de negocios y sitios web personalizada, que evaluó cada nombre y sitio web devuelto por la IA.
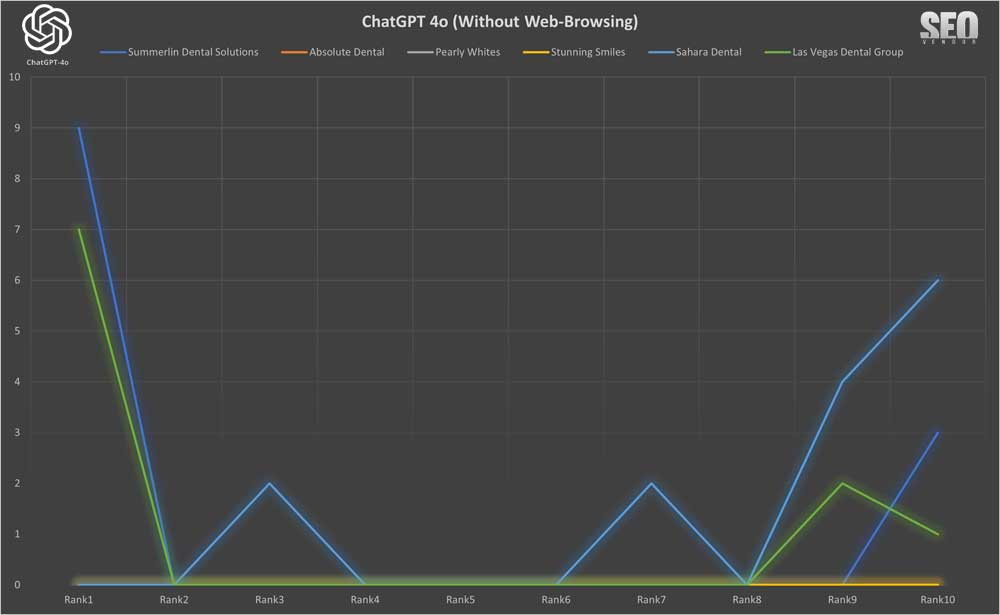
50X ChatGPT sin navegación web
Apariencia de la marca en 50 muestras sin navegación web ( Gráfico 1 ): Este gráfico ilustra la superposición en las recomendaciones de marca sin navegación en 50 muestras, mostrando nombres de empresas repetidos en cada muestra. El eje Y corresponde a la posición de una marca en la lista devuelta por GPT-4o, mientras que el eje X muestra la iteración en tiempo de ejecución.
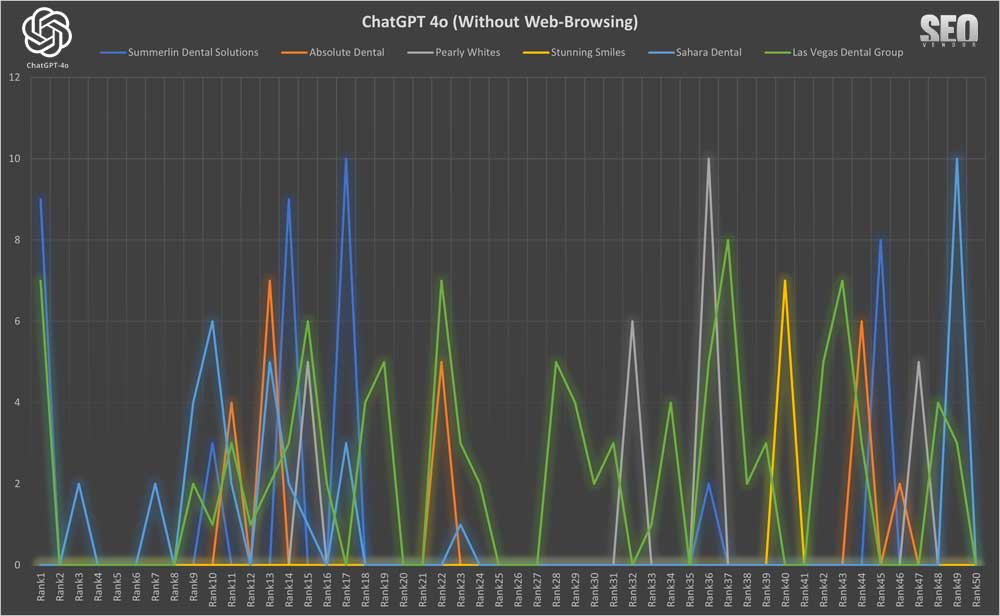
Podemos observar que la apariencia de una marca, en 50 iteraciones, parece bastante dispersa, sin una cohesión aparente entre la marca y cómo GPT-4o la muestra en los resultados. Aquí, la clasificación se determina como la posición en la lista de resultados devueltos por GPT-4o. Una empresa que obtuvo una alta clasificación en una iteración puede tener una clasificación baja o inexistente en la siguiente.
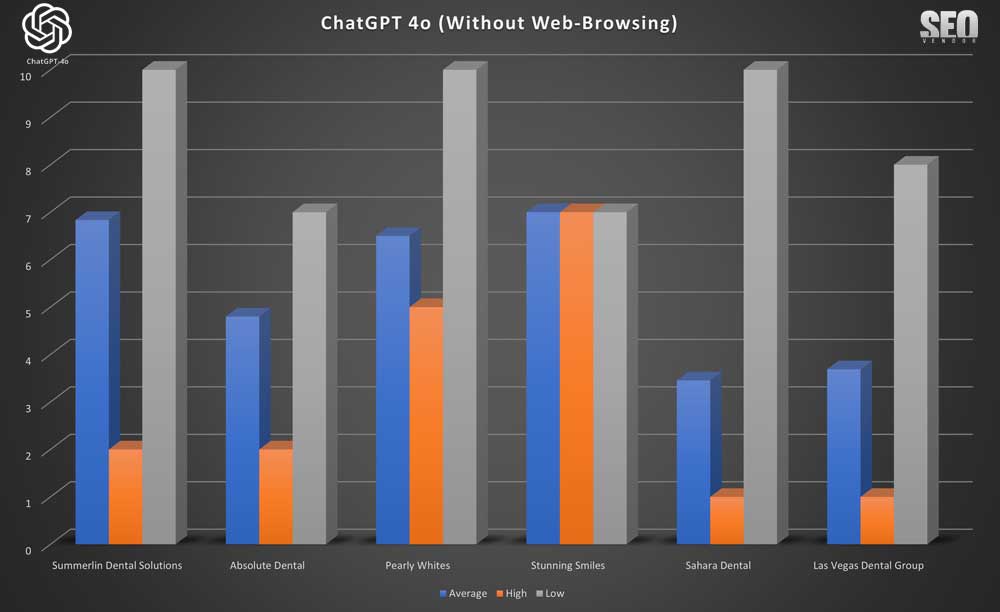
En
el Gráfico 2 , comparamos las clasificaciones (promedio, alto, bajo) de seis marcas seleccionadas al azar. Observamos una gran discrepancia entre las clasificaciones altas y bajas. No parece haber un orden específico al calcular las cifras, ya que se eliminaron los valores cero. De lo contrario, los promedios reales en 50 iteraciones serían mucho menores, ya que la aleatoriedad de los resultados hace que las marcas aparezcan con poca frecuencia, como se observa en el Gráfico 1. En el caso de Stunning Smiles, el promedio coincide con los de bajo y alto, ya que solo apareció una vez en 50 iteraciones.
El gráfico 3 muestra que, a pesar de la aleatoriedad, la frecuencia de aparición de un sitio web sigue generando una curva de gradiente, donde un pequeño número de sitios aparece con mucha más frecuencia que la mayoría. La lista completa sería mucho más larga, pero estas son las apariciones más frecuentes que se muestran en el gráfico.
Nota sobre las alucinaciones: Cabe destacar que mantuvimos «Dentistas de Las Vegas» y «Dentista de Las Vegas», entre otros, en el Gráfico 3 para poder observar la frecuencia de entidades dentales falsas o inventadas. La mayoría de estas entradas falsas tenían un dígito bajo y se eliminaron durante el análisis de datos.
Aplicaciones en el mundo real
En aplicaciones prácticas, ChatGPT sin navegación web puede encontrarse no solo mediante el uso de la API, sino también en ciertas instancias de la aplicación. Por ejemplo, con la navegación desactivada, modelos como ChatGPT-o1, ChatGPT 3.5 o GPT personalizados con navegación web desactivada siguen sin tener acceso al contenido web (al momento de escribir este artículo). La mayoría de los usuarios de pago de ChatGPT experimentarán cierto nivel de navegación web; por lo tanto, también presentamos ejemplos de búsquedas de navegación web a continuación.
ChatGPT 50X con búsqueda en la web
Apariencia de marca para 50 muestras con búsqueda mediante navegación web (gráfico 4) : este gráfico muestra cómo la navegación web influyó en la variedad de empresas recomendadas, lo que permitió a GPT-4o brindar recomendaciones más nuevas.
La búsqueda web proporciona a GPT-4o resultados de Bing para que disponga de datos en tiempo real. Hemos comprobado que proporcionar resultados de Bing tiene un gran impacto en el posicionamiento de cada empresa. Hemos observado que, en más de 50 muestras, los posicionamientos tienden a ser mucho más estables que sin navegación web, ya que GPT-4o asume los resultados de Bing con una ponderación significativa de los sitios que considera en sus resultados.
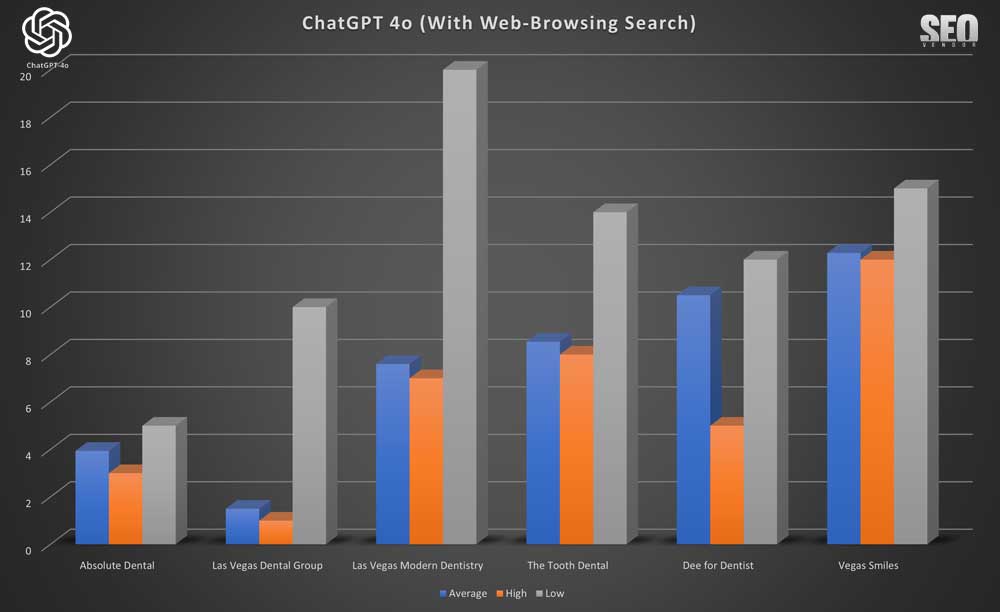
El Gráfico 5, «Apariencia de marca para 50 muestras con búsqueda web», destaca el impacto positivo de los datos en tiempo real en la calidad de las recomendaciones, incluyendo empresas populares que podrían no haber estado en el conjunto de entrenamiento original de GPT-4o. Con muy pocas excepciones, observamos menos cambios entre las clasificaciones bajas y altas, lo que también estabilizó las posiciones promedio.
Al analizar los resultados de un muestreo de 50 veces con resultados de búsqueda ( Gráfico 6 ), observamos una disminución drástica de la aleatoriedad y una mayor consistencia en las empresas que aparecen. Como era de esperar, la mayoría parece provenir de los resultados de búsqueda de Bing.
Aplicaciones en el mundo real
Las funciones de navegación web ofrecen un modelo más preciso de cómo la mayoría de las personas usan ChatGPT, ya que añadir la navegación web tiene un impacto significativo en los resultados de los datos más recientes. Sin embargo, según nuestros hallazgos, no es la solución definitiva.
ChatGPT irá un paso más allá al analizar los resultados de búsqueda y los fragmentos para ofrecer recomendaciones. Por lo tanto, también debemos tener en cuenta los casos en que esto ocurre.
Luego de realizar las pruebas de muestreo, disponemos de una gráfica que explica cómo se pueden distribuir los resultados entre los diferentes métodos.
50X ChatGPT con lectura de navegación web
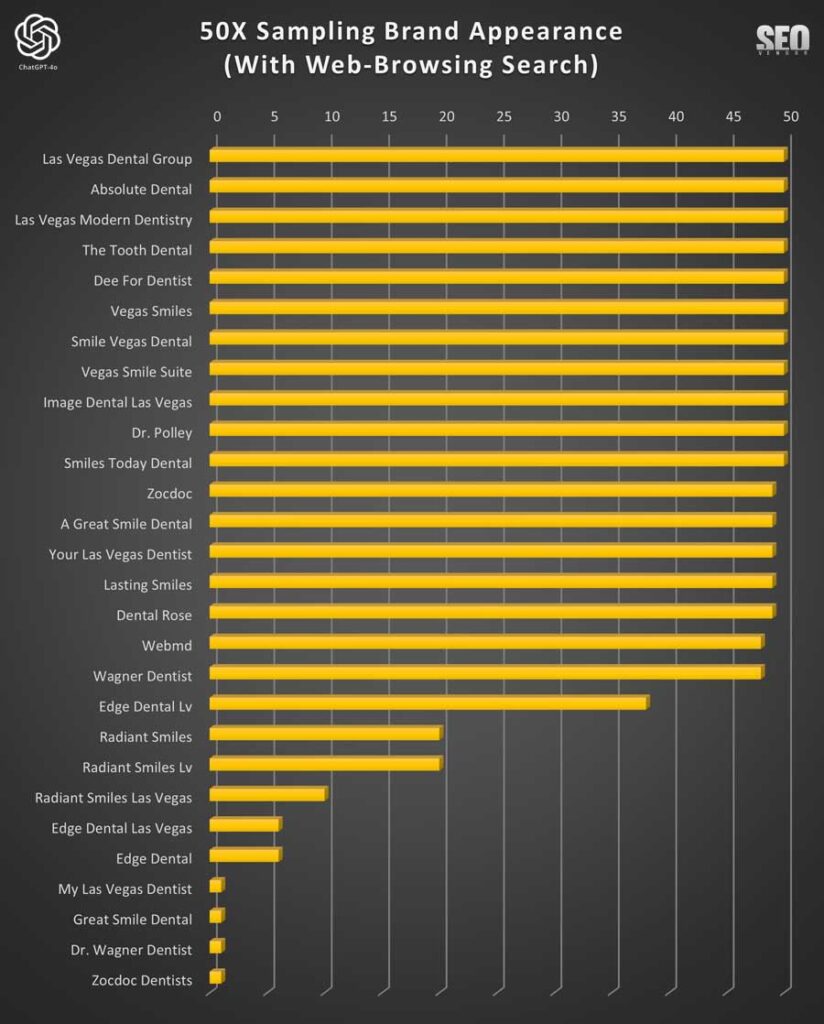
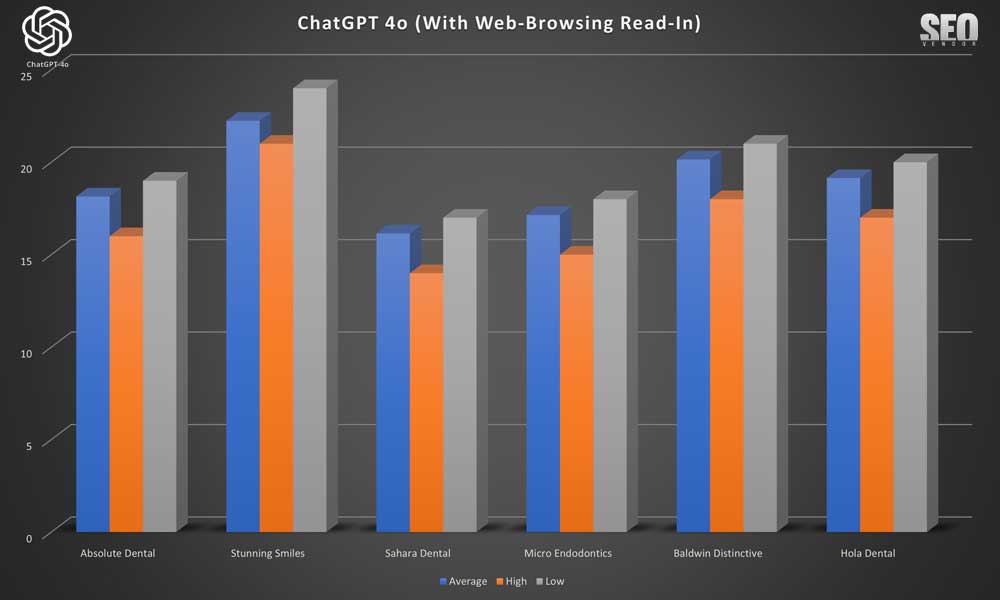
Apariencia de marca para 50 muestras con lectura en navegación web (gráfico 7) : un vistazo a cómo habilitar la lectura ayudó a identificar negocios especializados y altamente calificados que, de otro modo, se habrían pasado por alto.
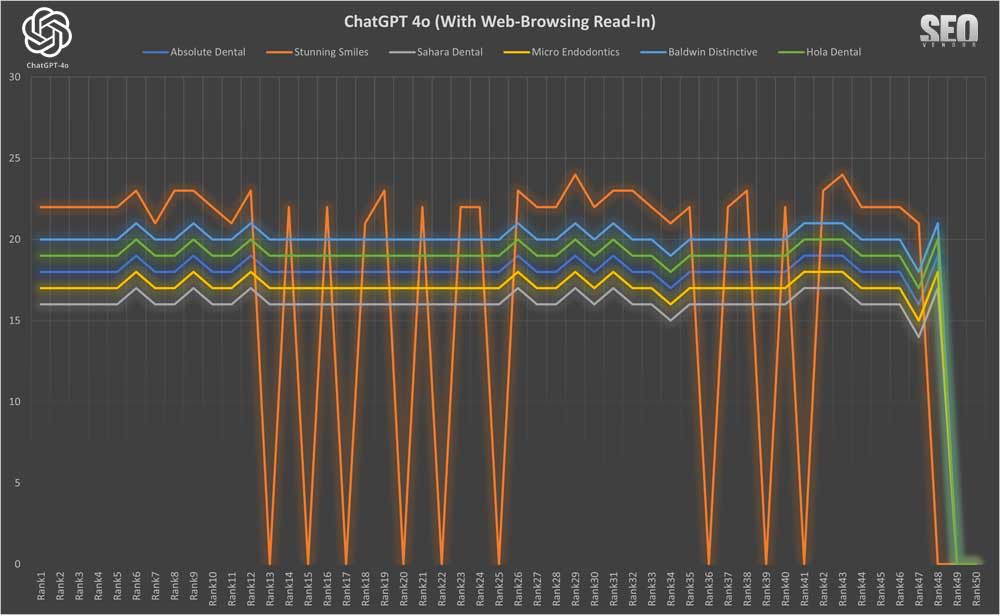
Al analizar los resultados de las clasificaciones selectivas de Read-In sobre navegación web, observamos una consistencia similar con solo la navegación web. Observe que una de las muestras, «Sonrisas Impresionantes», desapareció completamente de las clasificaciones ocasionalmente.
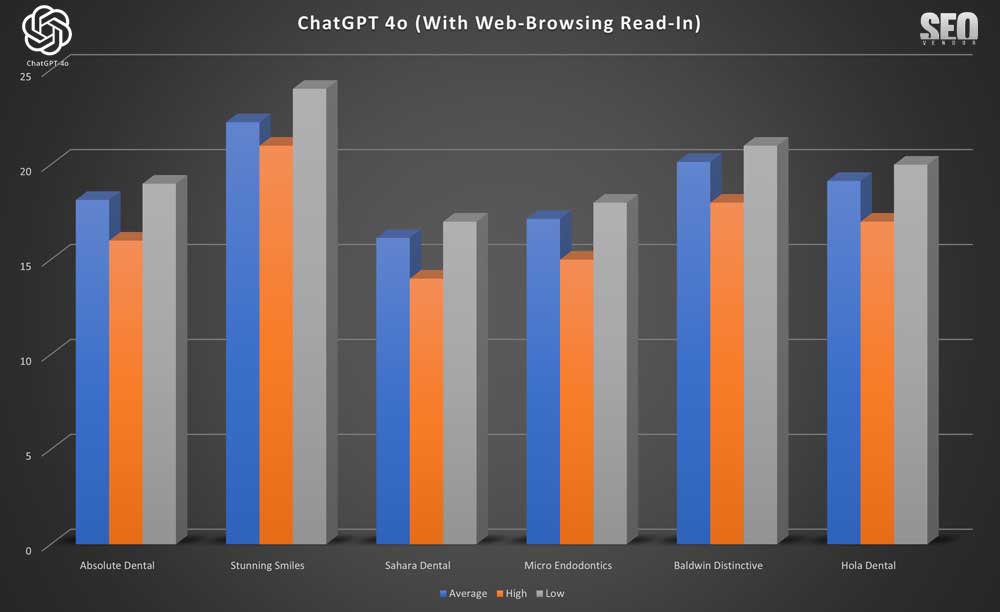
La apariencia de marca para 50 muestras con Read-In de navegación web (Gráfico 8) muestra menciones específicas de dentistas especializados y su consistencia en las muestras, tanto en las clasificaciones altas como bajas. En todas las pruebas, observamos que Read-In proporcionó los promedios más consistentes, dado que no contabilizamos las iteraciones donde no hubo clasificación.
El gráfico a continuación proporciona una mejor idea de la frecuencia de aparición, mientras que el gráfico 8 se centra en la frecuencia con la que apareció una empresa cuando había clasificaciones.
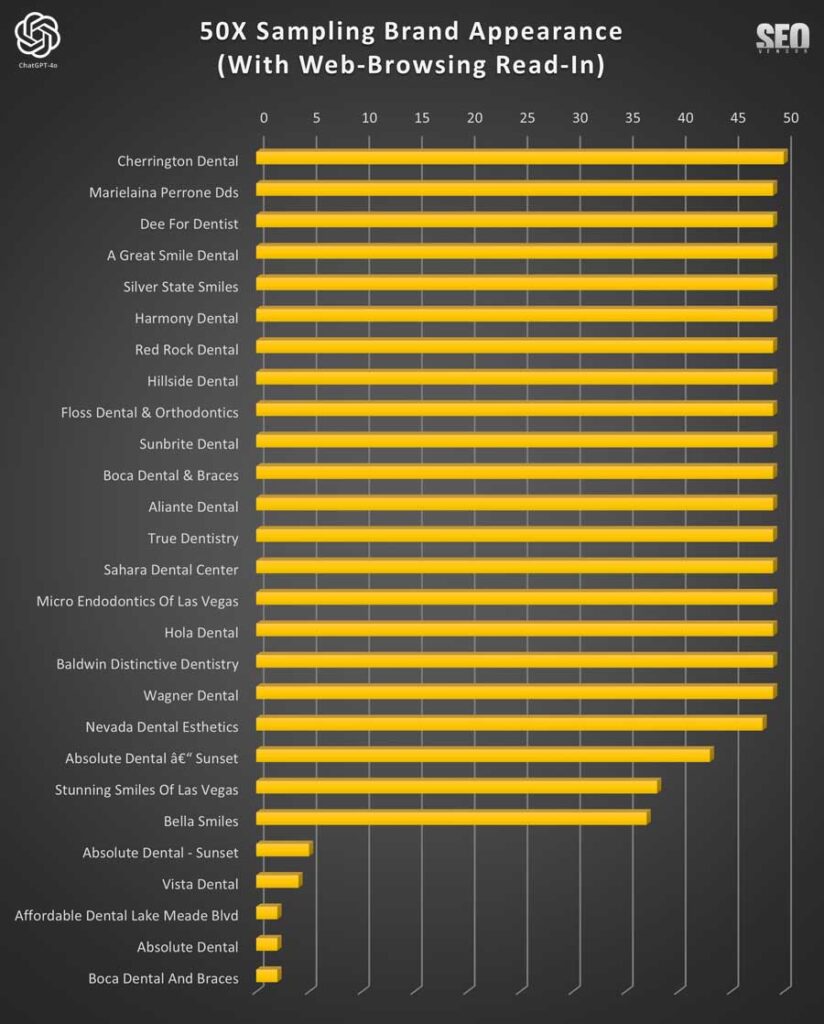
La mayoría de las marcas que aparecieron en el Gráfico 9 reaparecieron consistentemente en casi todas las 50 iteraciones. Hubo algunos valores atípicos donde la marca devuelta por ChatGPT no alcanzó nuestro umbral de similitud del 90 %. Por lo tanto, algunas, como Absolute Dental y Boca Dental, aparecerán más de una vez.
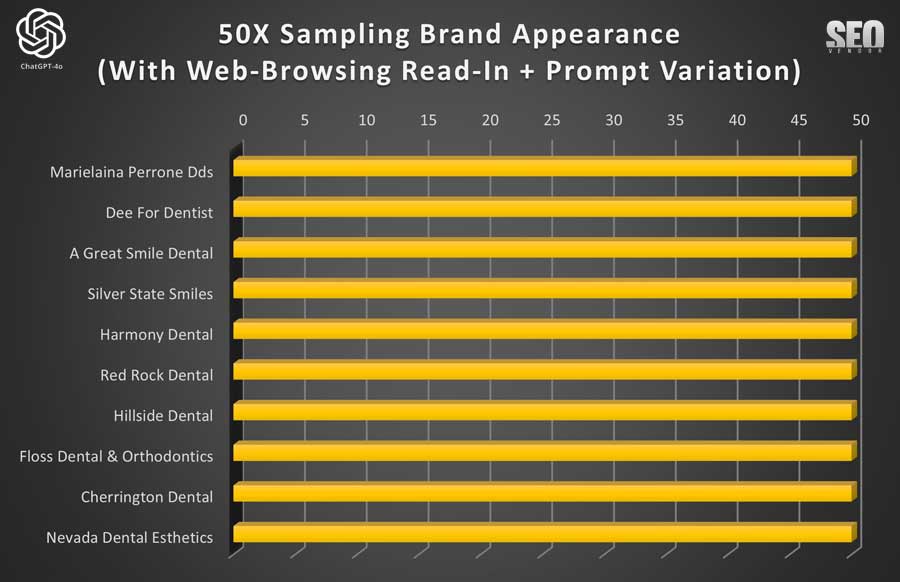
Lectura de navegación web 50X ChatGPT + variación de mensaje
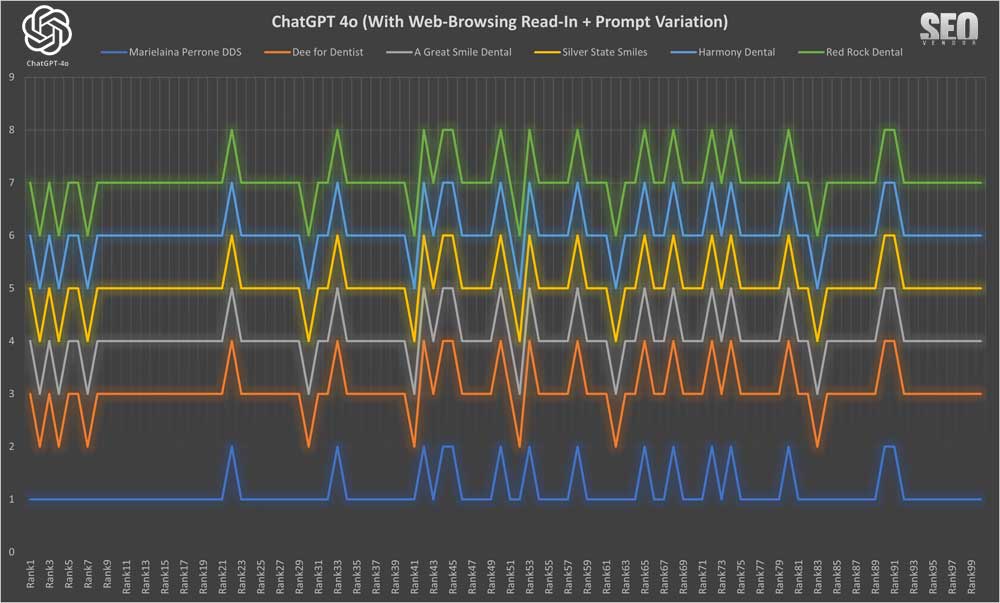
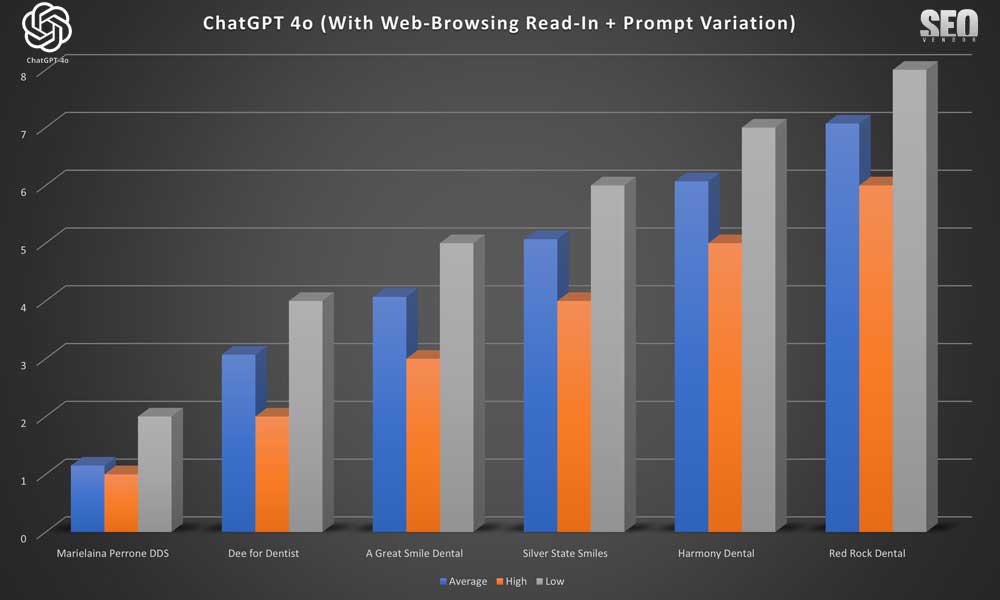
Apariencia de la marca para 50 muestras con lectura de navegación web + variación de indicaciones (Gráfico 10) : Demuestra cómo las variaciones de indicaciones permitieron a GPT-4o diversificar potencialmente sus respuestas. Sin embargo, en nuestro caso, observamos un impacto mínimo o nulo en los resultados. Para nuestra sorpresa, las variaciones (al menos en la forma en que las presentamos) no resultaron en una gama más amplia de recomendaciones de dentistas.
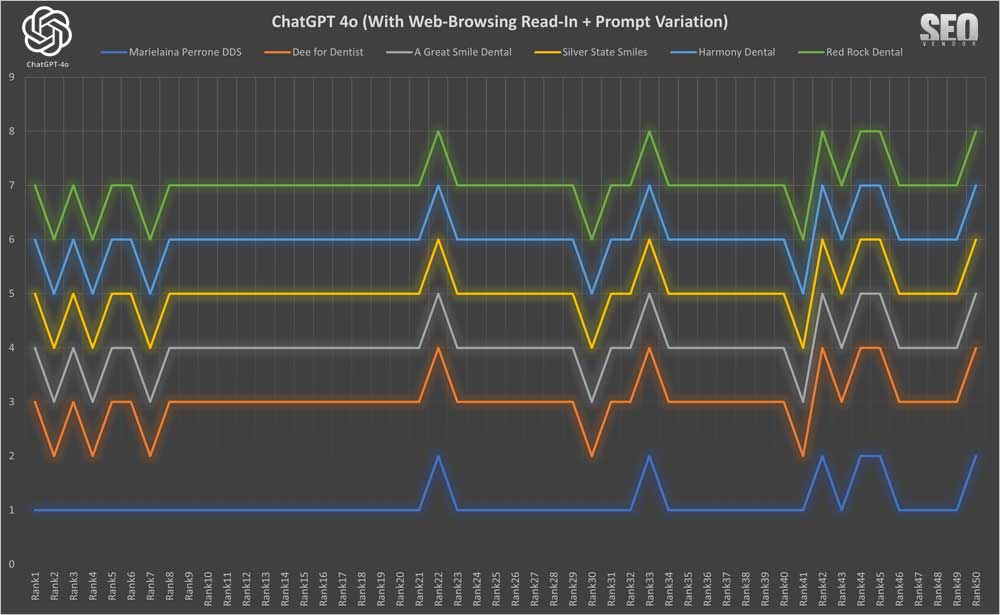
En cambio, la mayoría de las empresas se mantuvieron en sus posiciones. Sin embargo, se recomendó un grupo muy diferente de dentistas. No obstante, estas recomendaciones se mantuvieron prácticamente en la misma posición a pesar de las diferencias en las indicaciones. Nuestra teoría es que podría haber algún caché subyacente en OpenAI que esté analizando indicaciones similares, o quizás buscando resultados similares. Sin embargo, no tenemos forma de determinarlo con certeza.
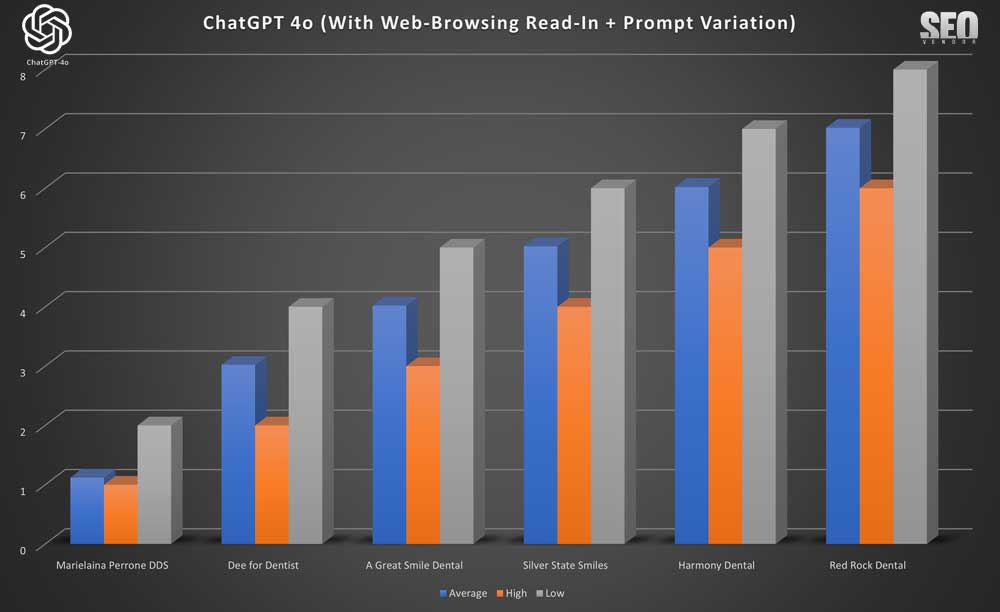
Apariencia de marca para 50 muestras con lectura de navegación web + variación de la indicación (Gráfico 11) : Un análisis más detallado de cómo la redacción de indicaciones menores influyó en el negocio recomendado. Sorprendentemente, las variaciones en las indicaciones no aumentaron la variación en los resultados, sino que la redujeron.
Investigamos esto y descubrimos que la variación del mensaje en sí tendría que ser muy diferente para que existieran diferencias. Por lo tanto, los cambios en la redacción no afectaron los resultados ( Gráfico 12 ), siempre que el significado sea el mismo. Si cambiar una palabra cambia el significado, los resultados serían completamente diferentes. Por otro lado, decir lo mismo de otra manera no alteró los resultados.
Lo que sucedió fue que los resultados parecieron no tener ninguna “caída” ya que cada variación de solicitud se ejecutó 10 veces y esas 10 no generaron ninguna desviación adicional en los resultados.
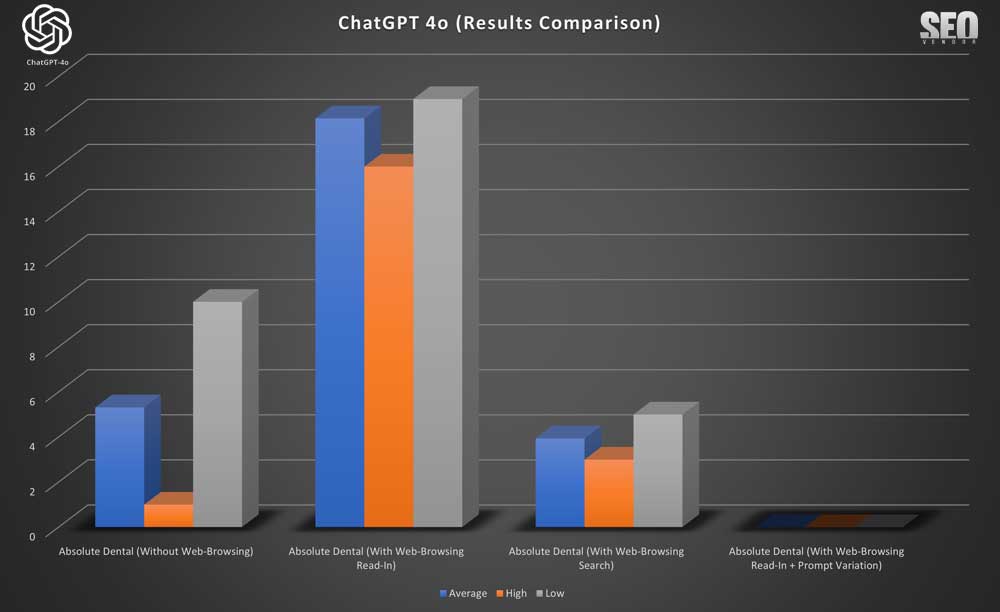
Para profundizar un poco más, quisimos comparar los cuatro métodos experimentales para una marca que aparecía con frecuencia, por lo que elegimos Absolute Dental. Los resultados del
Gráfico 13 mostraron que las clasificaciones de navegación web se mantuvieron estables en las pruebas de muestreo que incluyeron navegación web. Sin embargo, dado que la variación en la velocidad no resultó en ninguna clasificación para Absolute Dental, comparamos otra clínica dental en su lugar ( Gráfico 14 a continuación).
Descubrimos que una marca puede experimentar una mayor estabilidad a lo largo de las iteraciones si la navegación web está activada, pero las clasificaciones pueden variar significativamente según los resultados de búsqueda o la información de Read-In. En cambio, si la navegación web está desactivada, pueden producirse variaciones en la clasificación en cada iteración.
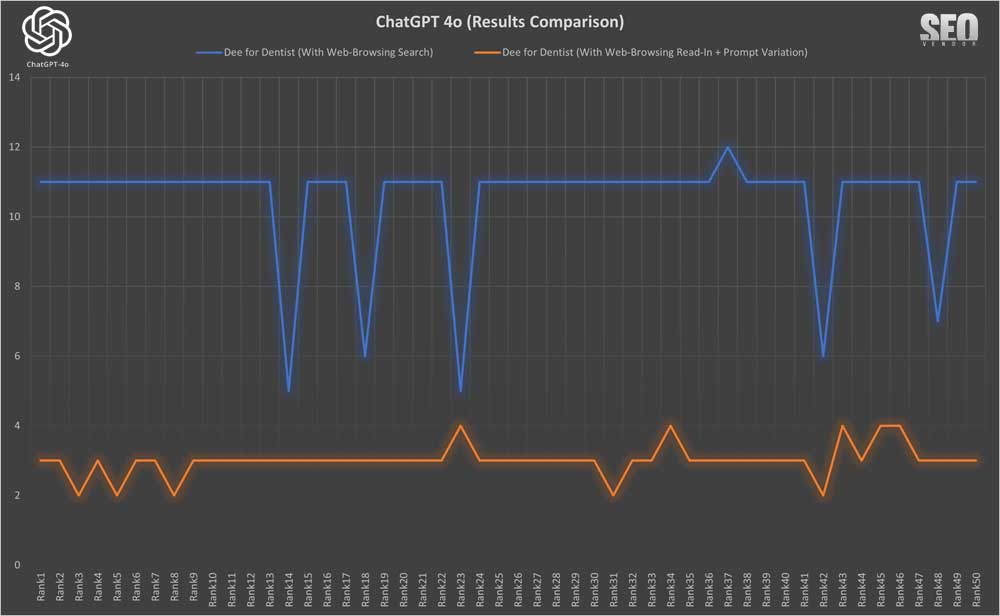
Cuando comparamos la búsqueda de navegación con la lectura en pantalla + variación del mensaje, encontramos que los resultados en el Gráfico 15 son similares, lo que demuestra aún más que los resultados de las variaciones del mensaje que no afectan el significado tampoco tendrán un peso significativo en las clasificaciones.
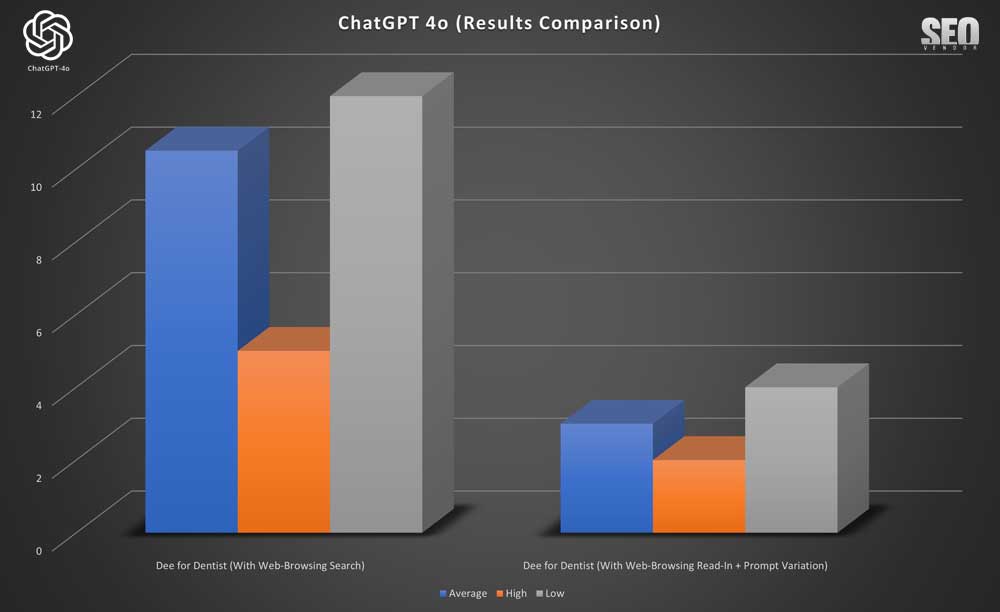
Podemos observar que la navegación web (con la variación de la indicación Read-In+) en el caso de Dee for Dentist ( Gráfico 16 ) resulta en una mejor clasificación en comparación con la búsqueda por navegación. Sin embargo, también podría haber sido cierto que las clasificaciones con la variación de la indicación disminuyeron o se desplomaron por completo, como en el caso de Absolute Dental.
Hallazgos clave para 50 muestras
- Menos superposición de marcas en condiciones de no navegación :
- “Sin navegación web” mostró una menor superposición en las marcas recomendadas, como “Absolute Dental” y “Las Vegas Dental Group”, consistente en los múltiples mensajes.
- Indica acceso limitado a fuentes de información RAG (Recuperación-Generación Aumentada), lo que resulta en una mayor variación en los resultados.
- Menos diversidad de marcas con búsqueda en la web :
- Cuando GPT-4o utilizó las capacidades de búsqueda de navegación web, las recomendaciones del modelo se limitaron a empresas como “The Tooth Dental” y “Las Vegas Modern Dentistry”.
- Destaca la importancia del acceso en tiempo real a las búsquedas web para influir en las respuestas del modelo.
- Variación rápida y diversidad empresarial :
- Con las variaciones rápidas combinadas con la navegación web, la diversidad en las recomendaciones en realidad disminuyó.
- Marcas específicas como “Dee for Dentist” y “Silver State Smiles” aparecieron de forma destacada, lo que sugiere que la redacción no afectó la variedad de empresas recomendadas siempre que el significado fuera el mismo.
- Énfasis en los nombres populares :
- En todas las condiciones, “Absolute Dental” apareció de manera consistente, independientemente de las capacidades de navegación o las variaciones de indicaciones.
- Esto sugiere un sesgo inherente hacia marcas conocidas que persiste incluso cuando está habilitada la navegación en tiempo real.
- Efecto de la lectura de la navegación web :
- “With Web-Browsing Read-In” produjo recomendaciones de marca más específicas.
- Se destacaron proveedores como “Cherrington Dental” y “Red Rock Dental”, lo que demuestra que la capacidad de leer contenido web específico generó recomendaciones más alineadas con los dentistas reseñados o destacados.
- Precisión en los nombres de marca :
- Las condiciones de navegación habilitadas proporcionaron nombres comerciales más precisos y completos.
- En comparación con la opción «Sin navegación web», se encontraron menos imprecisiones o etiquetas genéricas como «Dentista de Las Vegas». Esto sugiere que la función de navegación web minimiza eficazmente los errores relacionados con los nombres de empresas.
- Los gráficos comparativos muestran la coherencia con las capacidades de navegación :
- Los gráficos que comparan los resultados en diferentes condiciones indican que la navegación (tanto la búsqueda como la lectura) proporciona más consistencia en las respuestas a través de múltiples indicaciones, con menos valores atípicos y menciones más frecuentes de consultorios dentales mejor calificados.
- La repetición aumenta con la navegación :
- Hubo más repetición en los negocios recomendados cuando se habilitaron las capacidades de navegación.
- Por ejemplo, nombres como “Las Vegas Dental Group” aparecieron con mayor frecuencia en las muestras cuando se utilizó la navegación web, lo que demuestra que el modelo accedió a un rango limitado de fuentes.
Resultados del muestreo iterativo 100X
Nuestra investigación más exhaustiva consistió en probar 100 iteraciones de muestreo con ChatGPT. Si bien no esperamos que nadie utilice las indicaciones de esta manera en la práctica, el proceso nos ayuda a comprender la fiabilidad y la variabilidad en la forma en que ChatGPT proporciona respuestas.
Al ejecutar 100 iteraciones, pudimos obtener información valiosa sobre ChatGPT que no era posible con ejecuciones más cortas.
ChatGPT 100X sin navegación web
Primero, analizamos la apariencia de la marca para 100 muestras sin navegación web (Gráfico 17) . Este gráfico ilustra la frecuencia de las recomendaciones de marca empresarial al utilizar GPT-4o sin navegación web. Destaca la repetición y la superposición de marcas seleccionadas y su frecuencia de aparición.
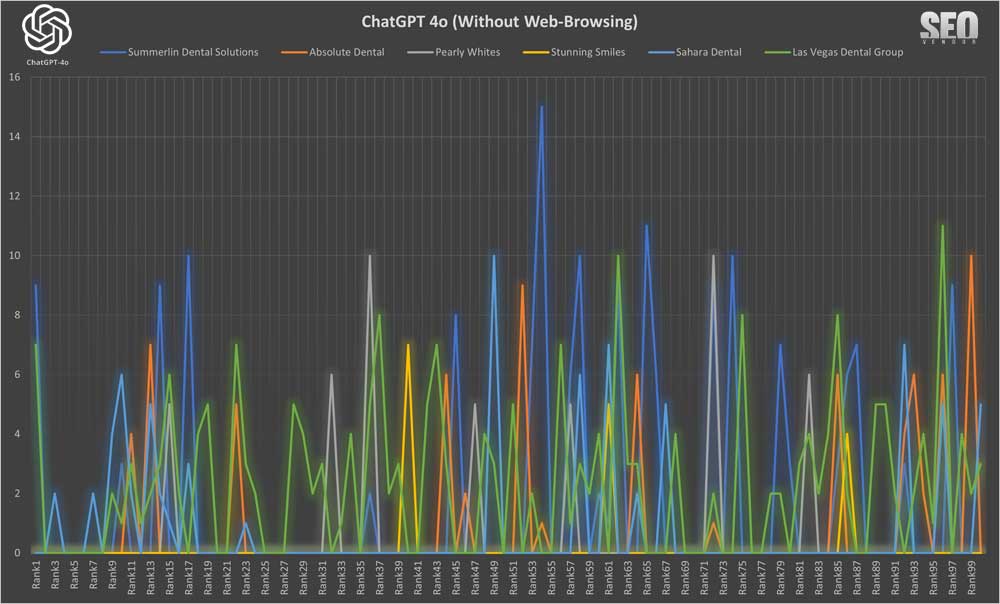
A partir de esto, podemos determinar que la dispersión de la visibilidad empresarial, la alta varianza en las clasificaciones y la aparición (o ausencia) de las clasificaciones se distribuyeron a lo largo de las pruebas de muestreo. Además, indicó que, sin navegación web, GPT-4o necesitaba una muestra amplia para determinar la probabilidad de aparición de una empresa.
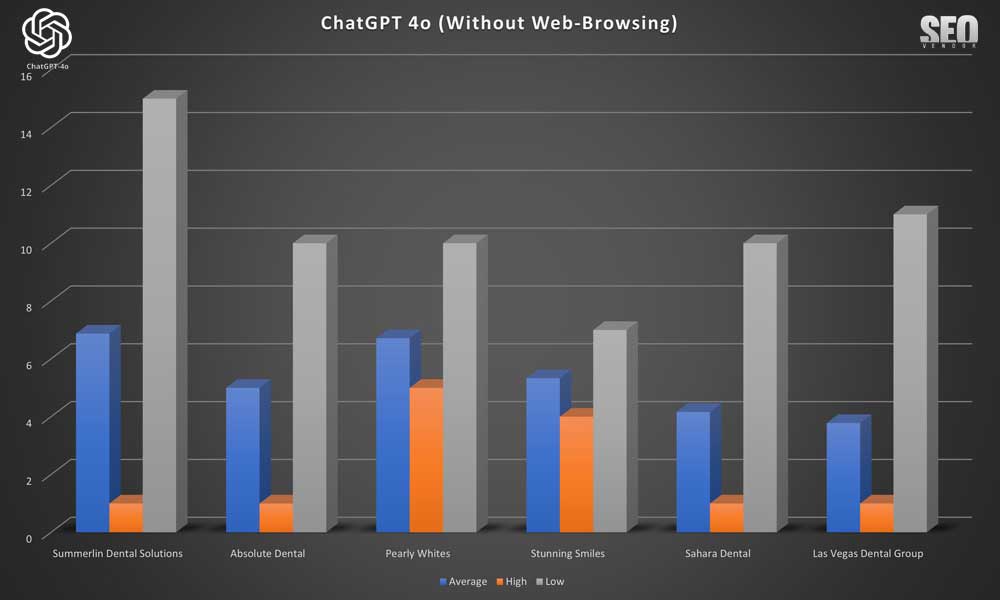
En el Gráfico 18 , observamos la variación en las recomendaciones de marca en 100 muestras sin funcionalidades de navegación web. Muestra las marcas más recomendadas y su consistencia en las diferentes indicaciones.
Nota: Una observación importante fue el aumento de marcas o sitios web alucinados que aparecieron durante el muestreo 100X. En nuestras pruebas, validamos todos los negocios e incluimos intencionalmente en el gráfico los resultados principales agregados, incluso aquellos como «El dentista en Las Vegas» y «Dentistas de Las Vegas», para observar su frecuencia de aparición.
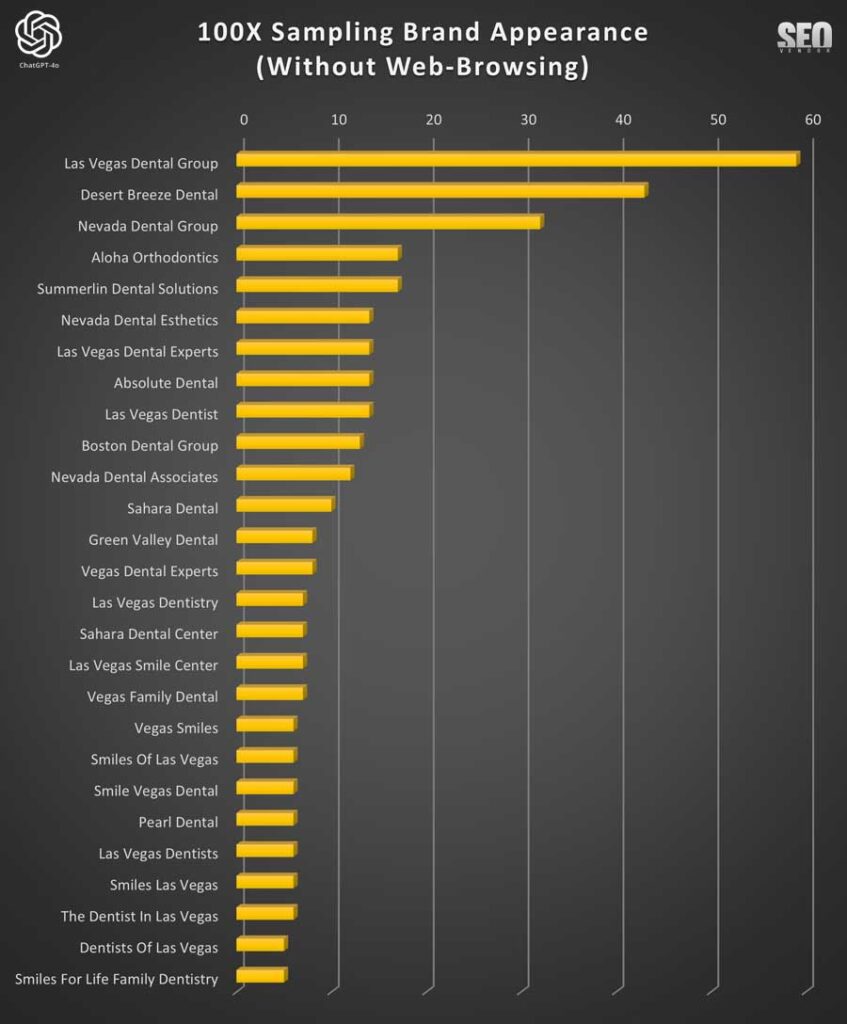
En el Gráfico 19, observamos que, según el conocimiento de la capacitación interna de ChatGPT, existía un sesgo inherente hacia ciertas empresas. Esto se evidencia en el número de veces que cada empresa apareció tras la misma solicitud.
ChatGPT 100X con búsqueda web
El Gráfico 20 muestra la apariencia de la marca en 100 muestras con búsqueda web . Este gráfico muestra las empresas recomendadas por GPT-4o cuando se habilitaron las funciones de búsqueda web, mostrando una mayor uniformidad en comparación con la condición sin navegación.
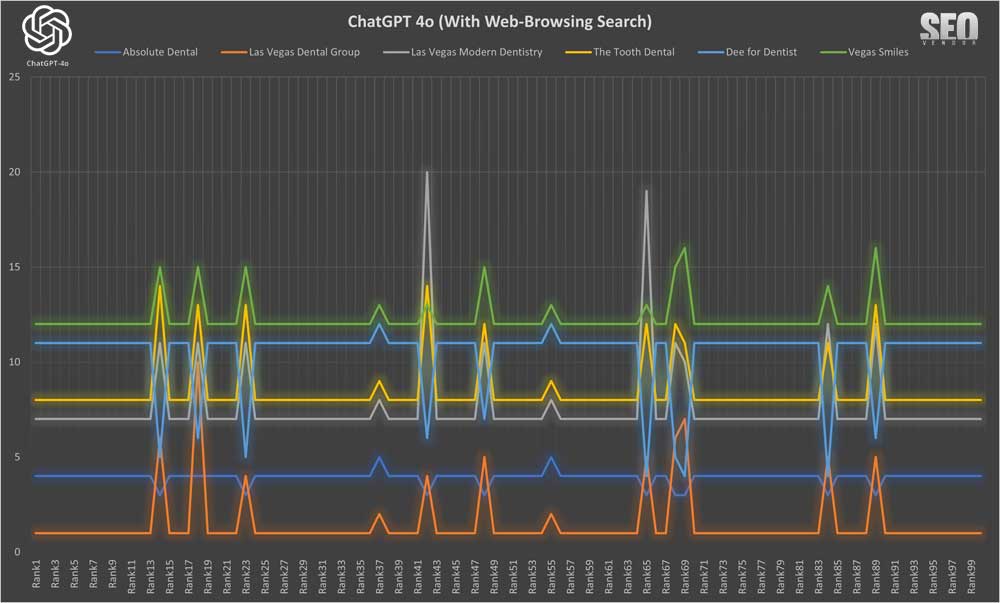
Podemos observar que las iteraciones más largas para el muestreo de búsquedas de navegación web no arrojaron una diferencia significativa con respecto al muestreo de 50X. La visualización detallada de la posición de la marca en 100 muestras destacadas (
Gráfico 21 ) muestra cómo ciertas marcas aún pueden dominar la presencia en ChatGPT. En algunos casos, también observamos una gran oscilación entre las posiciones más altas y más bajas de una marca.
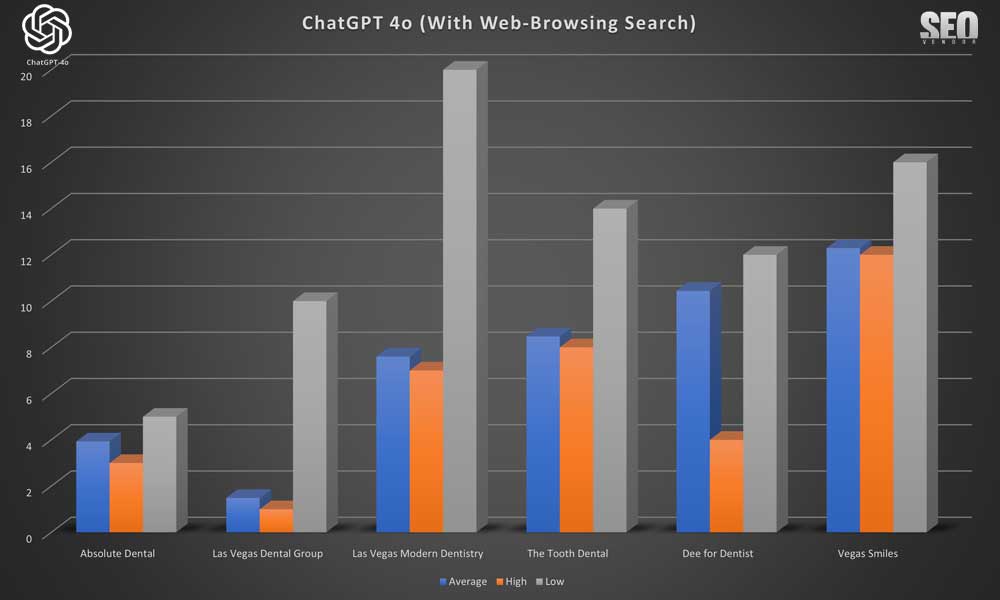
También podemos observar que, curiosamente, las empresas con las mejores clasificaciones promedio son también las que dominan cerca de la cima del gráfico de aparición (
Gráfico 22 ). Esto demuestra que las clasificaciones más bajas, en el caso de las búsquedas web, también influyen en la frecuencia de aparición.
Hemos determinado que los sitios que aparecen con menos frecuencia, especialmente aquellos que disminuyen significativamente, tienen más probabilidades de ser reemplazados por otras opciones. Por lo tanto, observamos una marcada disminución en la aparición de marcas que aparecen solo ocasionalmente.
ChatGPT 100X con lectura de navegación web
La apariencia de la marca para 100 muestras con lectura de navegación web (Gráfico 23) ilustra cómo las recomendaciones de GPT-4o mejoraron en especificidad y precisión al permitir la lectura de artículos. Muestra la variedad de dentistas recomendados y cómo la lectura afectó directamente la selección de empresas.
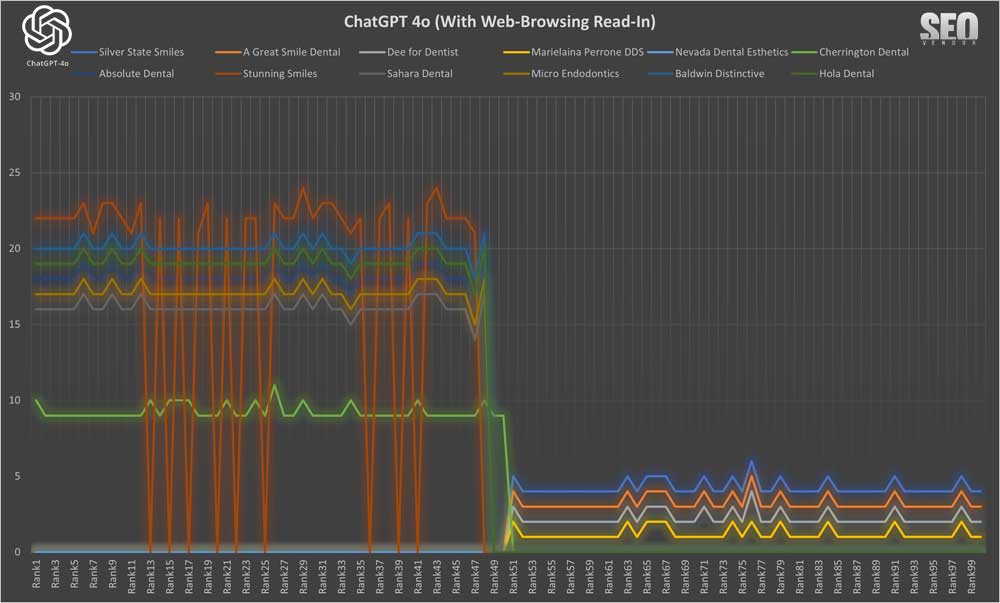
Una observación importante es la magnitud de los cambios en los resultados cuando cambia el contenido de la fuente. ¿A qué nos referimos con esto? Pudimos probar las condiciones que pueden darse durante periodos prolongados cuando la navegación web devuelve diferentes conjuntos de fuentes.
El material original puede cambiar por varios motivos:
- Cambios en la competencia. Por ejemplo, Sonrisas Impresionantes (Stunning Smiles) podía haber tenido una buena clasificación en Bing, pero ahora se enfrenta a una mayor competencia de clínicas dentales similares.
- Cambios en los algoritmos de búsqueda, que afectan los resultados devueltos por el motor de búsqueda.
- Actualizaciones del material original. Por ejemplo, si se eliminó Sonrisas Impresionantes de la lista de dentistas recomendados.
- Cambios en la propia empresa. Por ejemplo, si la empresa cerró, se fusionó o modificó su oferta de servicios, lo que afecta su aparición en los resultados de búsqueda.
Observamos cambios drásticos en las clasificaciones de los resultados de ChatGPT cuando esto ocurre. Dado que ChatGPT con navegación web se basa en datos de origen, los cambios en las propias fuentes pueden tener un impacto irreversible en algunas marcas durante la prueba de muestreo.
Además de descubrir cómo pueden aparecer o desaparecer las marcas, el gráfico 24 sobre la apariencia de marca de 100 muestras con lectura de navegación web muestra un análisis detallado de las menciones de proveedores de nicho cuando se habilitó la lectura, lo que indica un mayor acceso a proveedores con buenas reseñas pero menos conocidos.
Observamos que las diferencias entre las clasificaciones altas y bajas eran mínimas al eliminar las inapariciones (es decir, eliminar las muestras donde la clasificación era nula). Esto demuestra que, mientras la fuente permanezca igual, las clasificaciones son estables. Sin embargo, si la fuente analizada cambia, podemos esperar una fluctuación drástica en las clasificaciones.
En general, podemos ver en el Gráfico 25 que las empresas que permanecieron incluso después de los cambios de fuente mantuvieron sus recuentos de apariciones, mientras que aquellas que ya no aparecían vieron reducido drásticamente sus recuentos de apariciones.
Lectura de navegación web 100X ChatGPT + variación de mensaje
El gráfico 26 muestra la apariencia de la marca para 100 muestras con lectura de navegación web + variación de solicitud : este gráfico destaca cómo las variaciones de solicitud afectaron las recomendaciones de marca en 100 muestras.
Observamos con el material fuente que la variación de las indicaciones no alteró significativamente los resultados. Las clasificaciones se mantuvieron relativamente constantes. Se puede observar que algunas muestras desplazaron todas las clasificaciones en 1 punto hacia abajo, y que la práctica con la clasificación n.° 1 no se incluyó. Esto se debe a que, en algunas muestras, se devolvía un resultado no válido, que se descartaba.
El gráfico 27 muestra la apariencia de marca para 100 muestras con lectura de navegación web + variación de indicaciones. Analiza en profundidad cómo los pequeños cambios en la redacción de las indicaciones influyeron en el resultado y dieron lugar a pequeñas variaciones en las recomendaciones.
Esto es posible porque la variación del mensaje fue pequeña y no afectó la variación resultante entre las clasificaciones altas y bajas.
En el Gráfico 28: Apariencia de marca para 100 muestras con lectura de navegación web + variación de indicaciones , analizamos en profundidad cómo una redacción de indicaciones leve tiene un impacto mínimo o influye en la apariencia de una marca.

De manera similar al muestreo 50x, el Gráfico 28 demuestra que la lectura de las revisiones y recomendaciones solo solidificó la apariencia de cada negocio.
Hallazgos clave para 100 muestras
- ChatGPT-4o sin navegación web:
- En ausencia de capacidades de navegación web, las respuestas de GPT-4o se basaron únicamente en su conocimiento preexistente.
- Como era de esperar, las recomendaciones eran menos actualizadas y, a menudo, carecían de especificidad. En muchos casos, las respuestas incluían dentistas reconocidos, pero no necesariamente los más recientes ni los mejor valorados. También se observó un notable grado de aleatoriedad en las recomendaciones cuando el modelo se solicitó varias veces.
- ChatGPT-4o con búsqueda en la web:
- Cuando se le dio acceso a la navegación web, GPT-4o proporcionó respuestas significativamente mejoradas.
- El modelo logró incorporar información más actualizada, lo que generó recomendaciones que incluyeron dentistas más recientes y con mejores calificaciones. Curiosamente, la calidad de las respuestas mejoró en todas las preguntas multimuestra, lo que indica la ventaja de navegar para acceder a datos actualizados, pero también significó una menor variación en las respuestas.
- ChatGPT-4o con lectura de navegación web:
- En esta condición, GPT-4o no solo realizó una búsqueda sino que también leyó páginas web específicas relacionadas con la consulta.
- La capacidad de lectura adicional permitió que el modelo presentara recomendaciones más precisas en el contexto, a menudo haciendo referencia directa a artículos o revisiones de clasificación específicos.
- La consistencia entre las muestras también fue significativamente mayor en comparación con la condición sin navegación, es decir, a menos que cambie la fuente subyacente.
- ChatGPT-4o con lectura de navegación web + variación de mensaje:
- Pequeños cambios en la redacción no influyeron en los tipos de respuestas.
- La capacidad de lectura ayudó a mantener la coherencia a la hora de proporcionar respuestas actualizadas y completas.
- Las variaciones en la redacción de las indicaciones pusieron a prueba la solidez de las capacidades de exploración y comprensión de GPT-4o, mostrando que si bien la redacción de una indicación puede generar diferencias sutiles, el modelo generalmente mantuvo un estándar consistente de recomendaciones siempre que el material de origen permaneciera igual.
Resultados del muestreo iterativo 10X
Dejamos una de nuestras primeras pruebas para el final. Analizamos los números de cada prueba GPT-4o 10 veces. Tras revisar todos los datos de las pruebas 50X y 100X, nos dimos cuenta de que el muestreo 10X seguía siendo importante para comprender cómo se vería la variación en los resultados de GPT al muestrear a tasas bajas.
¿Por qué comprobar 10 iteraciones?
Un número bajo de iteraciones podría parecer insuficiente para un muestreo fiable, pero en la práctica, es poco probable que los usuarios ejecuten un mensaje 50 o 100 veces para determinar la verdadera apariencia de una marca. Un número bajo de muestras también podría proporcionar suficiente información; por lo tanto, probamos todos los casos de muestra a 10X.
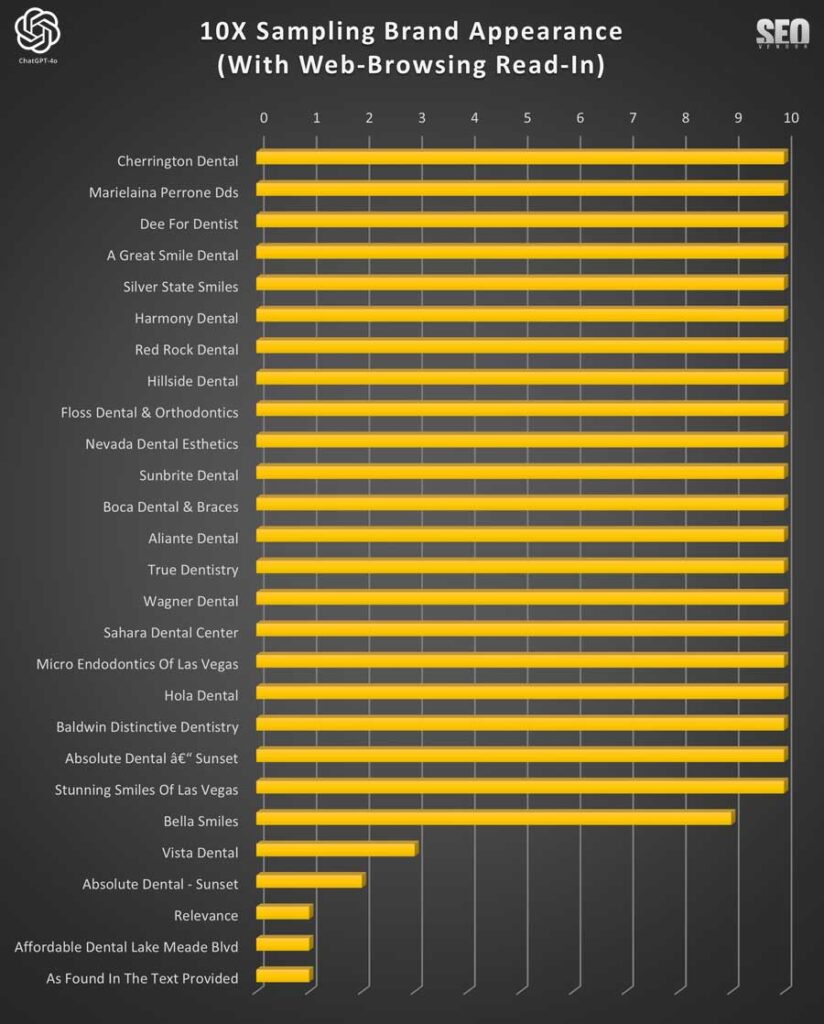
10X ChatGPT sin navegación web
Para rastrear el muestreo de 10X en relación con las mismas marcas que se rastrearon a 50X y 100X, graficamos seis marcas que aparecieron con frecuencia durante esas otras pruebas para determinar su visibilidad en el muestreo de 10X.
El Gráfico 29 muestra la
apariencia de la marca en 10 muestras sin navegación web . Este gráfico muestra las recomendaciones de marca en 10 muestras sin navegación web. Destaca la falta de diversidad, con negocios populares que se repiten con frecuencia. Además, observará que varios negocios que aparecían con frecuencia (Absolute Dental, Pearly Whites y Stunning Smiles) no aparecieron.
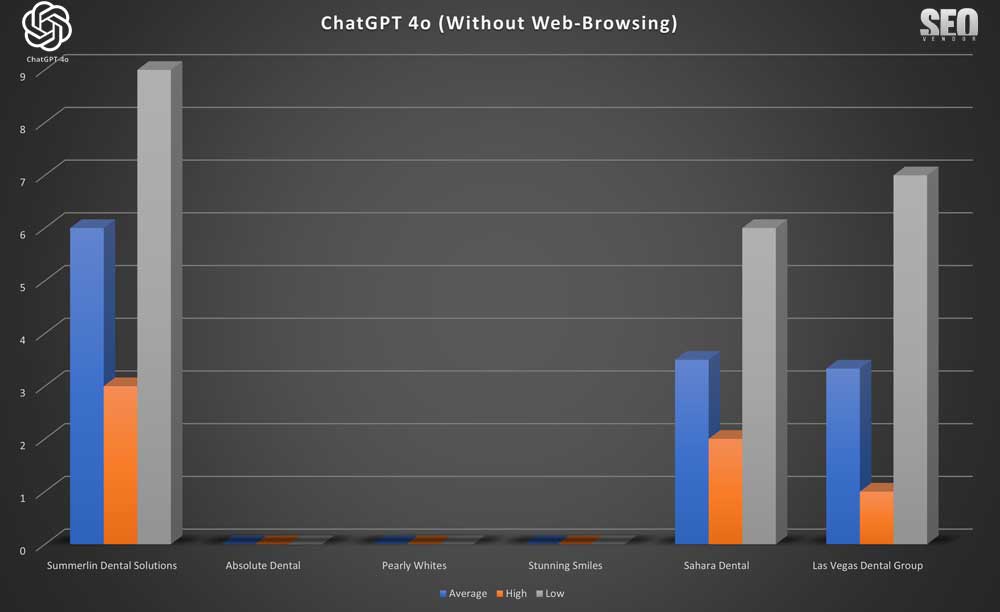
En
Apariencia de marca para 10 muestras sin navegación web (gráfico 30) , vemos detalles adicionales sobre la consistencia de ciertas marcas conocidas en 10 muestras, lo que muestra las limitaciones de no tener acceso a navegación pero también la misma alta variación en las clasificaciones.
En los recuentos acumulados de 10 muestras sin navegación web ( gráfico 31 ), podemos ver que puede haber un fuerte sesgo hacia una marca, con una disminución exponencial en la aparición de otras marcas.
ChatGPT 10X con búsqueda web
Los resultados del muestreo 10X con navegación web fueron aún más predecibles, ya que no observamos ningún cambio.
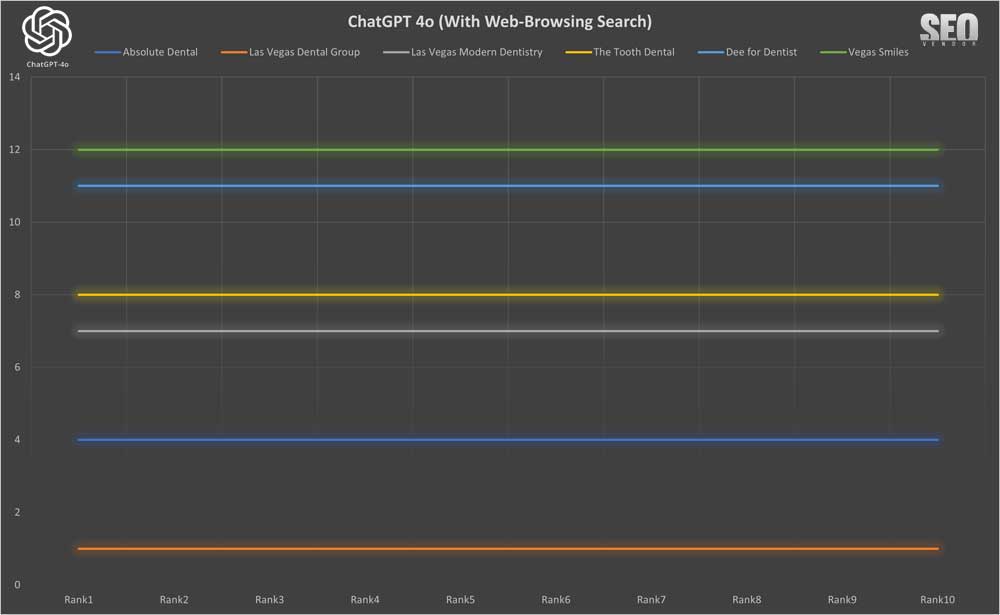
Dado que la tasa de muestreo fue baja,
la apariencia de marca para 10 muestras con búsqueda mediante navegación web (gráfico 32) demuestra cómo la incorporación de capacidades de búsqueda mediante navegación web “asegura” a las empresas recomendadas por GPT-4o.
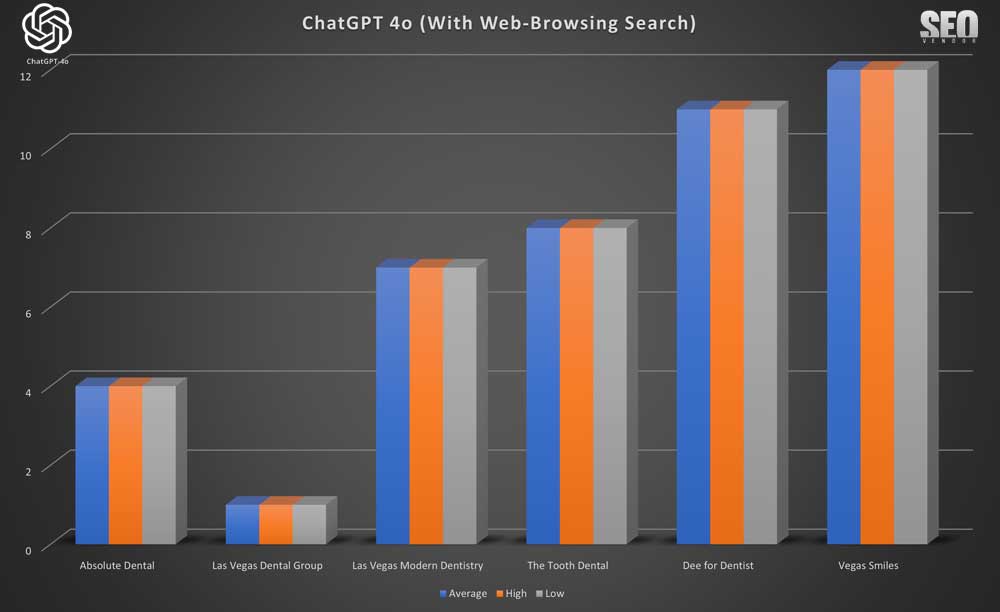
La apariencia de la marca para 10 muestras con búsqueda mediante navegación web (gráfico 33) destaca que no surgieron consultorios dentales más nuevos y diversos en los resultados debido al uso de navegación web en tiempo real; esencialmente, no hubo ningún cambio en absoluto.
El gráfico 34 demuestra que, con una tasa de muestreo baja y con la excepción de unos pocos profesionales, ChatGPT arrojó en su mayoría resultados consistentes.
10X ChatGPT con lectura de navegación web
Cuando introdujimos la lectura en el contenido, ChatGPT se comportó con una consistencia similar a la de tener capacidades de navegación web, pero con una variación ligeramente mayor en la apariencia.
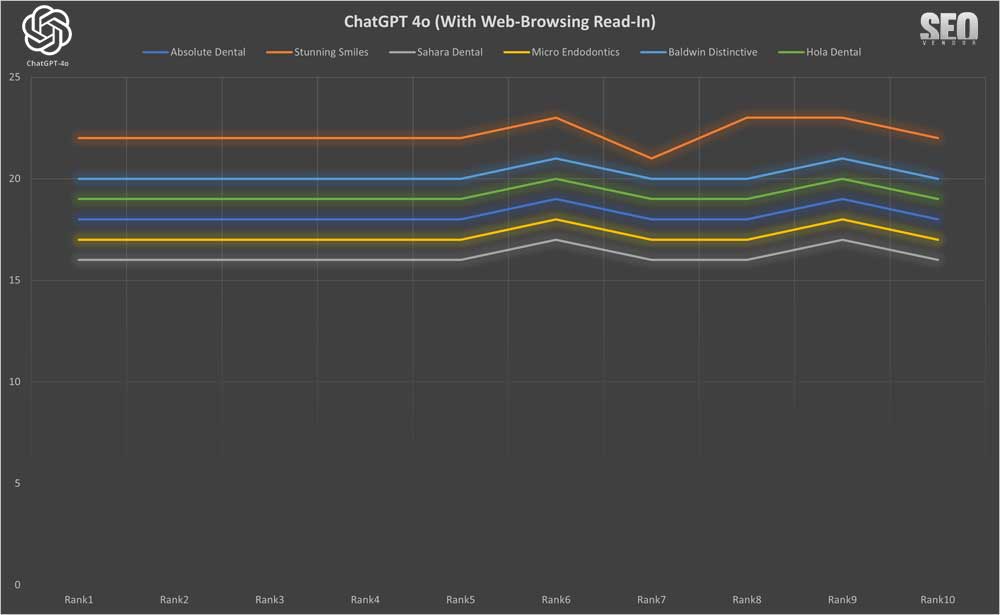
La apariencia de marca de 10 muestras con lectura de navegación web (Gráfico 35) muestra la influencia de la lectura de navegación web en las recomendaciones de GPT-4o. Si bien no necesariamente aumenta el número de proveedores de nicho en los resultados, sí modificó ligeramente su posición en el ranking.
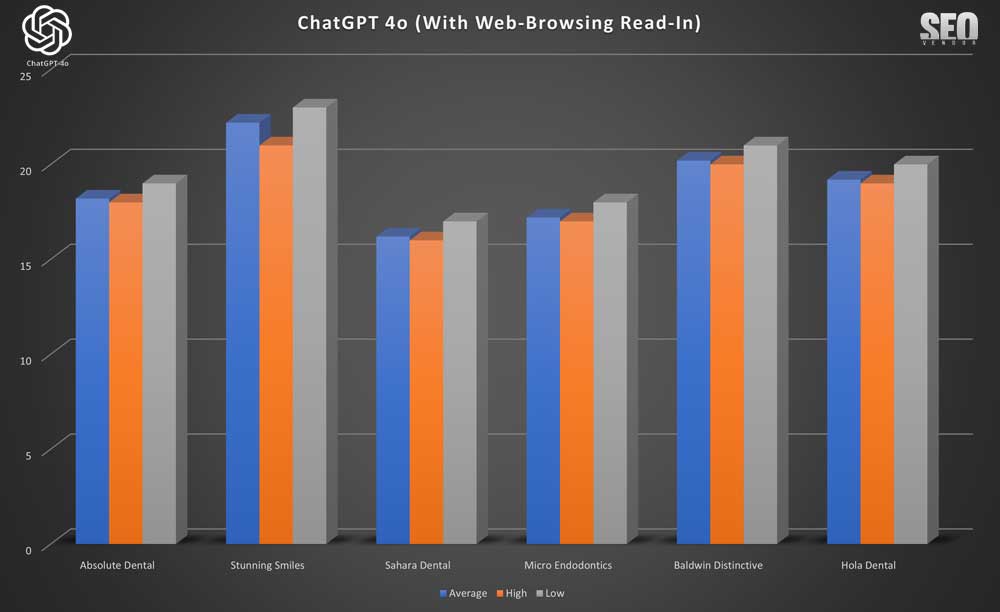
Podemos ver que debido a pequeños cambios en las clasificaciones, las clasificaciones máximas y mínimas en
Apariencia de marca para 10 muestras con lectura de navegación web (gráfico 36) no variaron mucho.
En general, la navegación web no mostró grandes cambios en el comportamiento con respecto a la navegación web estándar; sin embargo, observará que, incluso con un muestreo de 10X, el resultado principal cambió. Esto demuestra que la lectura de las recomendaciones de las fuentes de contenido aún influyó en la selección de dentistas.
ChatGPT 10X con lectura de navegación web y variación de indicaciones
También probamos un muestreo 10X con variaciones rápidas para comprender cómo las tasas de muestreo bajas afectaban la apariencia de la marca.
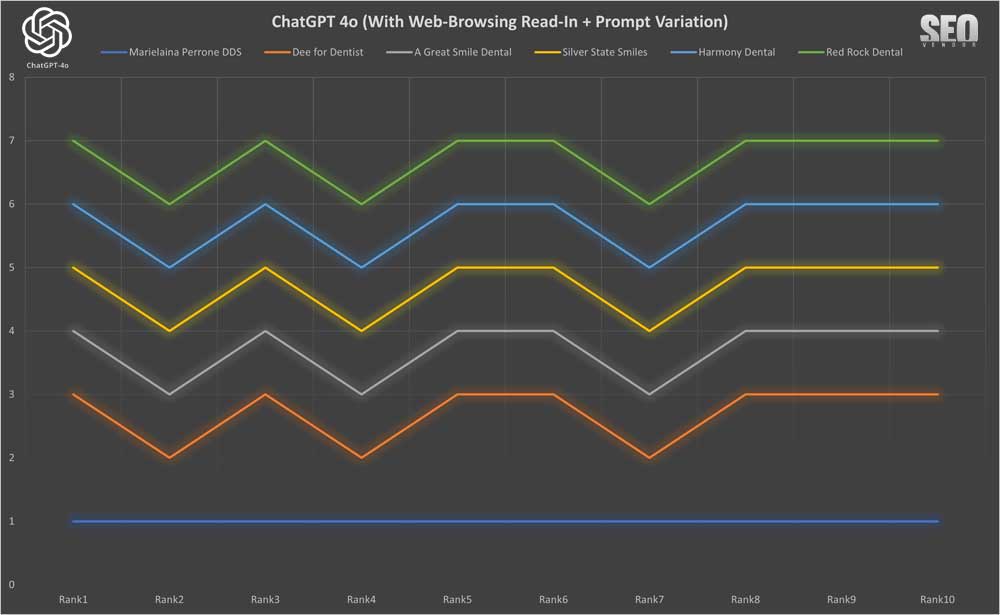
En el Gráfico 38 , Apariencia de marca para 10 muestras con lectura de navegación web + variación de mensaje , vemos cómo el uso de variaciones de mensaje influyó en los resultados de GPT-4o en cantidades mínimas.
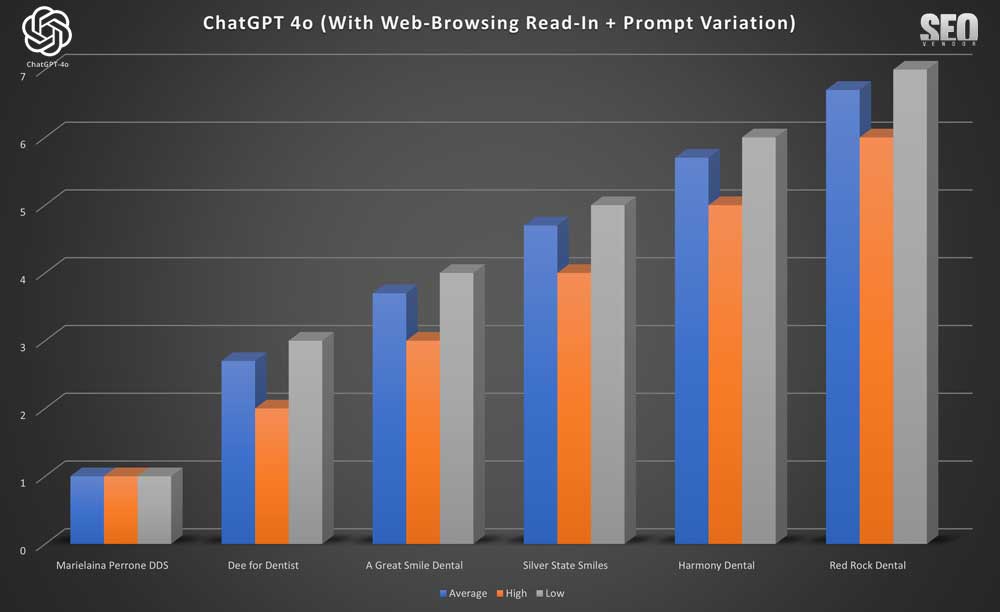
Cuando verificamos la
apariencia de la marca para 10 muestras con lectura de navegación web + variación de indicaciones (gráfico 39) , vimos un análisis detallado del efecto de la redacción de las indicaciones en el resultado, que muestra una menor cantidad de consultorios dentales únicos y diversos recomendados en comparación con 50X o 100X.
En el Gráfico 40, podemos observar que, al muestrear a baja tasa de marca frente a apariencia, no se observan cambios en la apariencia de cada marca. Esto significa que, a baja tasa de muestreo, las variaciones en la consigna tienen poco o ningún impacto. No se trata tanto de cómo esté escrita la consigna, sino de su significado.
Mientras el significado sea el mismo, los resultados probablemente también serán los mismos.
Hallazgos clave para 10 muestras
- Relevancia en el mundo real del muestreo de baja iteración:
- Las pruebas con 10 iteraciones reflejan el comportamiento típico del usuario, ya que es poco probable que la mayoría de los usuarios ejecuten los mensajes 50 o 100 veces.
- Los tamaños de muestra bajos aún pueden proporcionar información valiosa sobre la variación y confiabilidad de las respuestas de ChatGPT.
- 10X ChatGPT sin navegación web:
- Diversidad limitada en las recomendaciones:
- Los negocios populares se repitieron con frecuencia, lo que demuestra una falta de diversidad.
- Algunas marcas que aparecieron en pruebas de iteración superiores (Absolute Dental, Pearly Whites, Stunning Smiles) no aparecieron en absoluto.
- Sesgo hacia ciertas marcas:
- Se observó un fuerte sesgo hacia una marca, con una marcada disminución en la aparición de otras marcas.
- Alta variación en las clasificaciones:
- Las clasificaciones de las empresas recomendadas mostraron una variabilidad significativa entre iteraciones.
- Diversidad limitada en las recomendaciones:
- ChatGPT 10X con búsqueda web:
- Consistencia en los resultados:
- La adición de capacidades de navegación web “bloqueó” las empresas recomendadas, lo que dio como resultado resultados altamente consistentes.
- No surgieron consultorios dentales nuevos ni diversos; los resultados se mantuvieron iguales en todas las iteraciones.
- Previsibilidad:
- El uso de navegación web en tiempo real no introdujo cambios a esta frecuencia de muestreo.
- Consistencia en los resultados:
- 10X ChatGPT con lectura de navegación web:
- Ligero aumento de la varianza:
- La introducción de capacidades de lectura condujo a cambios menores en las posiciones de clasificación de algunos proveedores.
- El dentista más recomendado cambió, lo que indica que la lectura de fuentes de contenido tuvo algún impacto.
- Se mantiene la consistencia general:
- A pesar de ligeras variaciones, el comportamiento general se mantuvo similar a la navegación web estándar.
- Ligero aumento de la varianza:
- ChatGPT 10X con lectura de navegación web y variación de mensaje:
- Impacto mínimo de las variaciones de las indicaciones:
- Las variaciones en la formulación de las indicaciones tuvieron poco o ningún efecto sobre los resultados a tasas de muestreo bajas.
- El significado del mensaje influyó más en los resultados que la redacción específica utilizada.
- Coherencia en la apariencia de la marca:
- No se observó ningún cambio significativo en la apariencia de las marcas en comparación con otras pruebas 10X.
- Impacto mínimo de las variaciones de las indicaciones:
- Observaciones generales:
- Impacto de la tasa de muestreo:
- Las tasas de muestreo bajas dan como resultado una alta consistencia y una diversidad limitada en las recomendaciones.
- Es más probable que se observen cambios significativos en la apariencia de la marca con un muestreo de iteración más alto.
- Importancia del significado de Prompt:
- La intención subyacente del mensaje es crucial: mientras el significado siga siendo el mismo, es probable que los resultados sean consistentes.
- Efecto de las capacidades de navegación:
- Las funciones de navegación web y lectura mejoran la coherencia, pero no necesariamente incrementan la diversidad a tasas de muestreo bajas.
- Impacto de la tasa de muestreo:
Conclusión de la prueba final
Este estudio exhaustivo demuestra la variabilidad y adaptabilidad de GPT-4o para generar recomendaciones empresariales en diferentes condiciones de solicitud. La incorporación de funciones de navegación y lectura mejoró notablemente la relevancia y la calidad de las recomendaciones proporcionadas. Sin embargo, el estudio también destaca la sensibilidad (o inexistencia) de los LLM a la formulación de solicitudes, lo que sugiere que la forma en que un usuario formula una consulta no siempre influye en el resultado.
Desde una perspectiva de marketing, esto es lo que hemos aprendido:
- La marca será una señal importante para tener presencia en los LLM.
- Los LLM como ChatGPT están capacitados con un amplio conocimiento de marcas y sitios web de pequeñas empresas.
- El conocimiento empresarial en ChatGPT dista mucho de ser perfecto. Puede confundir nombres o crear variaciones incorrectas de ellos.
- El conocimiento del sitio web es incluso peor que el conocimiento de la marca en ChatGPT.
- Los chatbots son cada vez más importantes para las empresas. Se necesitan más pruebas como estas.
A medida que los LLM continúan evolucionando, comprender el impacto de la redacción rápida, las capacidades de navegación y la recuperación de datos RAG en su rendimiento será crucial para optimizar su uso en aplicaciones comerciales del mundo real, como GAIO (Optimización generativa de IA).
Esperamos que los conocimientos adquiridos en este estudio ofrezcan una guía valiosa para las empresas y los desarrolladores que buscan aprovechar los LLM para crear u optimizar sistemas de clasificación/recomendación de LLM y casos de uso similares.
*Estudio original SEO Vendor.



Deja una respuesta